
容器的兴起,kubernetes已成为大家追捧的容器集群管理系统。Prometheus作为生态圈CNCF中重要一员,活跃程度仅次于kubernetes,现在已经成为kubernetes集群的监控系统。
Prometheus简介
Prometheus是一套开源的系统监控报警框架,受启发与google的borgmon监控系统,由google前员工在2012年创建,作为社区项目开发,并正式在2015年发布,2016年,Prometheus 正式加入 Cloud Native Computing Foundation,成为受欢迎度仅次于 Kubernetes 的项目。
作为新一代的监控框架,Prometheus 具有以下特点:
- 强大的多维度数据模型
- 灵活而强大的查询语句(PromQL)
- 易于管理,单独的二进制文件
- 一个 Prometheus server可以处理数百万的 metrics
- 使用 pull 模式采集时间序列数据
- 可以采用 push gateway 的方式把时间序列数据推送
- 通过服务发现或者静态配置去获取监控的 targets
- 多种可视化图形界面
数据采集可能会有丢失,所以Prometheus不适用对采集数据要 100% 准确的情形。但如果用于记录时间序列数据,Prometheus 具有很大的查询优势,此外,Prometheus 适用于微服务的体系架构。
Prometheus组成
- Prometheus Server: 用于收集和存储时间序列数据。
- Client Library: 客户端库,为需要监控的服务生成相应的 metrics 并暴露给 Prometheus server。当 Prometheus server 来 pull 时,直接返回实时状态的 metrics。
- Push Gateway: 主要用于短期的 jobs。由于这类 jobs 存在时间较短,可能在 Prometheus 来 pull 之前就消失了。为此,这次 jobs 可以直接向 Prometheus server 端推送它们的 metrics。这种方式主要用于服务层面的 metrics,对于机器层面的 metrices,需要使用 node exporter。
- Exporters: 用于暴露已有的第三方服务的 metrics 给 Prometheus。
- Alertmanager: 从 Prometheus server 端接收到 alerts 后,会进行去除重复数据,分组,并路由到对收的接受方式,发出报警。常见的接收方式有:电子邮件,webhook 等。
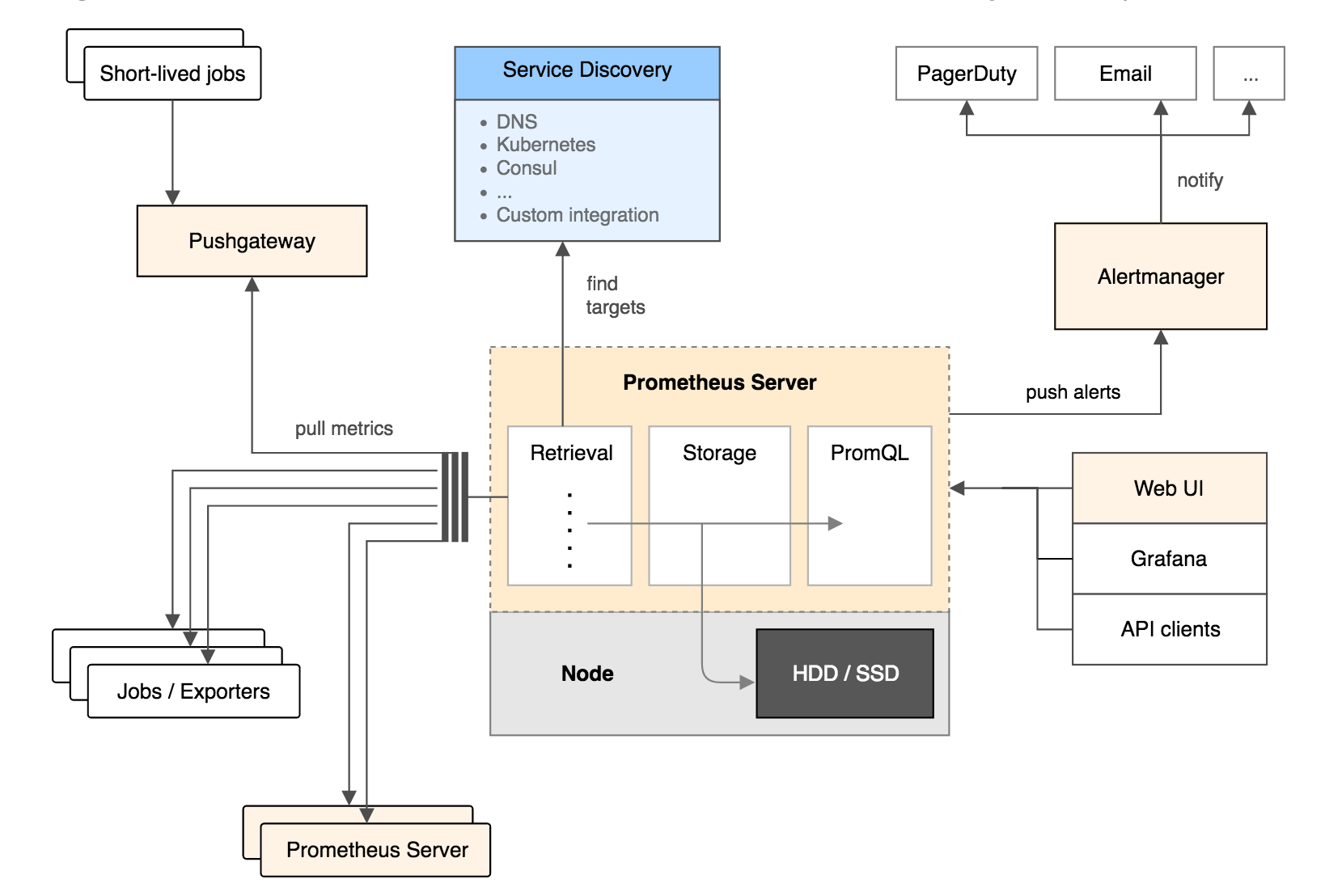
工作流程:
- Prometheus server 定期从配置好的 jobs 或者 exporters 中拉 metrics,或者接收来自 Pushgateway 发过来的 metrics,或者从其他的 Prometheus server 中拉 metrics。
- Prometheus server 在本地存储收集到的 metrics,并运行已定义好的 alert.rules,记录新的时间序列或者向 Alertmanager 推送警报。
- Alertmanager 根据配置文件,对接收到的警报进行处理,发出告警。
- 在图形界面中,可视化采集数据。
Prometheus 相关概念
数据模型
Prometheus中存储的数据为时间序列,是由 metric 的名字和一系列的标签(键值对)唯一标识的,不同的标签则代表不同的时间序列。
- metric名字: 该名字应该具有语义,一般用于表示 metric 的功能,其中,metric 名字由 ASCII 字符,数字,下划线,以及冒号组成,且必须满足正则表达式 [a-zA-Z_:][a-zA-Z0-9_:]*。
- 标签: 使同一个时间序列有了不同维度的识别。例如 http_requests_total{method=”Get”} 表示所有 http 请求中的 Get 请求。
- 样本: 实际的时间序列,每个序列包括一个 float64 的值和一个毫秒级的时间戳。
- 格式:http_requests_total{method=”POST”,endpoint=”/api/tracks”}。
四种Metric类型
- Counter: 一种累加的 metric。
- Gauge: 一种常规的 metric,可以任意加减。
- Histogram: 可以理解为柱状图,可以对观察结果采样,分组及统计
- Summary: 类似于 Histogram,提供观测值的 count 和 sum 功能,提供百分位的功能,即可以按百分比划分跟踪结果
instance 和 jobs
- instance: 一个单独 scrape 的目标, 一般对应于一个进程。
- jobs: 一组同种类型的 instances(主要用于保证可扩展性和可靠性)
Node exporter
Node exporter 主要用于暴露 metrics 给 Prometheus,其中 metrics 包括:cpu 的负载,内存的使用情况,网络等。
1 | ~]# wget https://github.com/prometheus/node_exporter/releases/download/v0.16.0/node_exporter-0.16.0.linux-amd64.tar.gz |
2 | ~]# tar xf node_exporter-0.16.0.linux-amd64.tar.gz |
3 | ~]# cd node_exporter-0.16.0.linux-amd64 |
4 | ~]# ./node_exporter |
5 | INFO[0000] Starting node_exporter (version=0.16.0, branch=HEAD, revision=d42bd70f4363dced6b77d8fc311ea57b63387e4f) source="node_exporter.go:82" |
6 | INFO[0000] Build context (go=go1.9.6, user=root@a67a9bc13a69, date=20180515-15:52:42) source="node_exporter.go:83" |
7 | INFO[0000] Enabled collectors: source="node_exporter.go:90" |
8 | INFO[0000] - arp source="node_exporter.go:97" |
9 | INFO[0000] - bcache source="node_exporter.go:97" |
10 | INFO[0000] - bonding source="node_exporter.go:97" |
11 | INFO[0000] - conntrack source="node_exporter.go:97" |
12 | INFO[0000] - cpu source="node_exporter.go:97" |
13 | INFO[0000] - diskstats source="node_exporter.go:97" |
14 | INFO[0000] - edac source="node_exporter.go:97" |
15 | INFO[0000] - entropy source="node_exporter.go:97" |
16 | INFO[0000] - filefd source="node_exporter.go:97" |
17 | INFO[0000] - filesystem source="node_exporter.go:97" |
18 | INFO[0000] - hwmon source="node_exporter.go:97" |
19 | INFO[0000] - infiniband source="node_exporter.go:97" |
20 | INFO[0000] - ipvs source="node_exporter.go:97" |
21 | INFO[0000] - loadavg source="node_exporter.go:97" |
22 | INFO[0000] - mdadm source="node_exporter.go:97" |
23 | INFO[0000] - meminfo source="node_exporter.go:97" |
24 | INFO[0000] - netdev source="node_exporter.go:97" |
25 | INFO[0000] - netstat source="node_exporter.go:97" |
26 | INFO[0000] - nfs source="node_exporter.go:97" |
27 | INFO[0000] - nfsd source="node_exporter.go:97" |
28 | INFO[0000] - sockstat source="node_exporter.go:97" |
29 | INFO[0000] - stat source="node_exporter.go:97" |
30 | INFO[0000] - textfile source="node_exporter.go:97" |
31 | INFO[0000] - time source="node_exporter.go:97" |
32 | INFO[0000] - timex source="node_exporter.go:97" |
33 | INFO[0000] - uname source="node_exporter.go:97" |
34 | INFO[0000] - vmstat source="node_exporter.go:97" |
35 | INFO[0000] - wifi source="node_exporter.go:97" |
36 | INFO[0000] - xfs source="node_exporter.go:97" |
37 | INFO[0000] - zfs source="node_exporter.go:97" |
38 | INFO[0000] Listening on :9100 source="node_exporter.go:111" |
39 | ~]# curl 127.0.0.1:9100/metrics |
Prometheus server
1 | ~]# cat prometheus.yml |
2 | global: |
3 | scrape_interval: 15s |
4 | evaluation_interval: 15s |
5 | |
6 | # Alertmanager configuration |
7 | alerting: |
8 | alertmanagers: |
9 | - static_configs: |
10 | - targets: |
11 | - 127.0.0.1:9093 |
12 | |
13 | rule_files: |
14 | - "rules.yaml" |
15 | |
16 | scrape_configs: |
17 | - job_name: 'prometheus' |
18 | |
19 | # metrics_path defaults to '/metrics' |
20 | # scheme defaults to 'http'. |
21 | |
22 | static_configs: |
23 | - targets: ['localhost:9090'] |
24 | |
25 | - job_name: 'node' |
26 | static_configs: |
27 | - targets: ['localhost:9100'] |
28 | labels: |
29 | group: 'dev' |
30 | severity: 'all' |
31 | |
32 | ~]# cat rules.yaml |
33 | groups: |
34 | - name: system |
35 | rules: |
36 | - alert: UP |
37 | expr: up == 0 |
38 | for: 1m |
39 | labels: |
40 | severity: all |
41 | annotations: |
42 | summary: "Instance {{$labels.instance}} down" |
43 | description: "{{$labels.instance}} of job {{$labels.job}} has been down for more than 1 minutes." |
44 | |
45 | ~]# ./prometheus --config.file=prometheus.yml |
46 | level=info ts=2018-11-04T11:58:17.147315438Z caller=main.go:238 msg="Starting Prometheus" version="(version=2.4.3, branch=HEAD, revision=167a4b4e73a8eca8df648d2d2043e21bdb9a7449)" |
47 | level=info ts=2018-11-04T11:58:17.147405776Z caller=main.go:239 build_context="(go=go1.11.1, user=root@1e42b46043e9, date=20181004-08:42:02)" |
48 | level=info ts=2018-11-04T11:58:17.147429336Z caller=main.go:240 host_details="(Linux 3.10.0-327.el7.x86_64 #1 SMP Thu Nov 19 22:10:57 UTC 2015 x86_64 INIT (none))" |
49 | level=info ts=2018-11-04T11:58:17.147447402Z caller=main.go:241 fd_limits="(soft=1024, hard=4096)" |
50 | level=info ts=2018-11-04T11:58:17.147461267Z caller=main.go:242 vm_limits="(soft=unlimited, hard=unlimited)" |
51 | level=info ts=2018-11-04T11:58:17.148494087Z caller=web.go:397 component=web msg="Start listening for connections" address=0.0.0.0:9090 |
52 | level=info ts=2018-11-04T11:58:17.148422011Z caller=main.go:554 msg="Starting TSDB ..." |
Alertmanager
1 | ~]# cat alertmanager.yml |
2 | global: |
3 | resolve_timeout: 5m |
4 | smtp_smarthost: 'smtp.163.com:25' |
5 | smtp_from: '13588722***@163.com' |
6 | smtp_auth_username: '13588722***@163.com' |
7 | smtp_auth_password: 'zgx710****' |
8 | |
9 | route: |
10 | group_by: ['alertname'] |
11 | group_wait: 10s |
12 | group_interval: 10s |
13 | repeat_interval: 1h |
14 | receiver: 'default' |
15 | routes: |
16 | - match: |
17 | severity: all |
18 | receiver: 'monitor' |
19 | |
20 | receivers: |
21 | - name: 'default' |
22 | email_configs: |
23 | - to: '710800***@qq.com' |
24 | ~]# ./alertmanager --config.file=alertmanager.yml |
25 | level=info ts=2018-11-04T12:17:17.213886691Z caller=main.go:174 msg="Starting Alertmanager" version="(version=0.15.2, branch=HEAD, revision=d19fae3bae451940b8470abb680cfdd59bfa7cfa)" |
26 | level=info ts=2018-11-04T12:17:17.213953739Z caller=main.go:175 build_context="(go=go1.10.3, user=root@3101e5b68a55, date=20180814-10:53:39)" |
27 | level=info ts=2018-11-04T12:17:17.241097409Z caller=cluster.go:155 component=cluster msg="setting advertise address explicitly" addr=10.211.55.6 port=9094 |
28 | level=info ts=2018-11-04T12:17:17.243555649Z caller=main.go:322 msg="Loading configuration file" file=alertmanager.yml |
29 | level=info ts=2018-11-04T12:17:17.243586224Z caller=cluster.go:570 component=cluster msg="Waiting for gossip to settle..." interval=2s |
30 | level=info ts=2018-11-04T12:17:17.246347278Z caller=main.go:398 msg=Listening address=:9093 |
31 | level=info ts=2018-11-04T12:17:19.243974745Z caller=cluster.go:595 component=cluster msg="gossip not settled" polls=0 before=0 now=1 elapsed=2.000320548s |
32 | level=info ts=2018-11-04T12:17:27.244897944Z caller=cluster.go:587 component=cluster msg="gossip settled; proceeding" elapsed=10.001241152s |