
什么是任务队列
任务队列被用作在线程或机器之间分配工作的机制,任务队列的输入是一个被称为任务的工作单元,专用的worker进程不断监视任务队列以执行新的工作,而celery通过broker的机制调节client与worker之间的消息传递,要初始化一条消息,client需要向broker传递一条消息,celery负责将消息代理传递给woker执行。
简单的原理: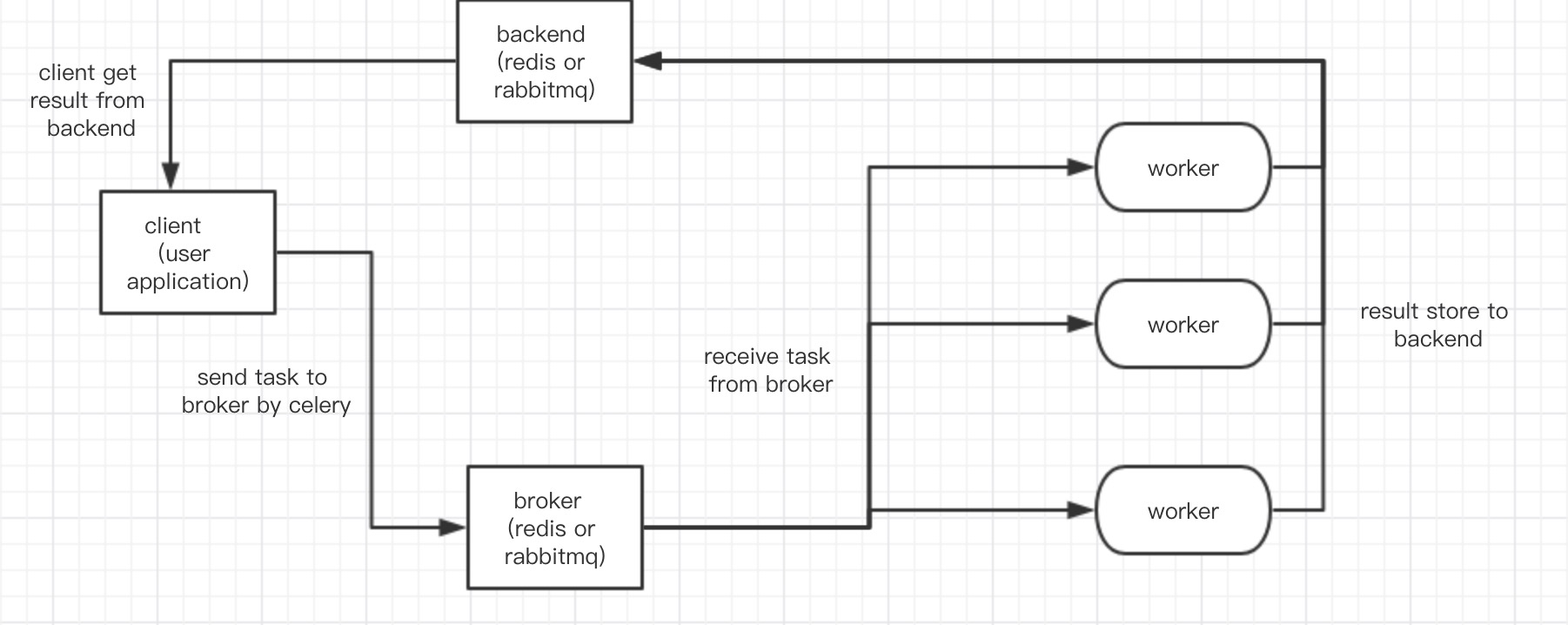
celery的执行过程也是异步过程,当需要执行的任务量巨大时,我们不能阻塞等待全部的任务的执行完成,而是只需要获得下发任务的唯一任务id,当需要的时候,我们可以通过这个任务id来获取我们需要的执行结果,所以这里也就需要一个中间件来存储任务结果,一般用的时rabbitmq或者redis,但经过自己的使用,redis来作为broker会出现不稳定的报错,所以还是建议rabbitmq使用。
celery的优点:
- 简单:整个celery的框架工作流程明了,并不复杂
- 高可用:worker和client将会重试连接失败或者失败的事件
- 快速:一个单进程的celery每分钟可以处理上百万的任务
- 灵活:提供了很强的扩展性,可以继承django等框架
安装celery
1 | ~]# pip install -U celery |
rabbitmq
rabbitmq是celery默认的broker
1 | app.conf.broker_url = "amqp://rabbitmq:rabbitmq@localhost:5672//test" |
2 | app.conf.result_backend = "amqp://rabbitmq:rabbitmq@localhost:5672//test" |
redis
redis需要额外的redis库支持,所以需要额外的安装redis
1 | pip install -U redis |
2 | pip install -U celery[redis] #在安装celery的时候,安装以来redis |
1 | app.conf.broker_url = 'redis://:password@localhost:6379/0' |
2 | app.conf.broker_url = 'redis+socket:///path/to/redis.sock?virtual_host=db_number' |
3 | # 哨兵集群 |
4 | app.conf.broker_url = 'sentinel://localhost:26379;sentinel://localhost:26380;sentinel://localhost:26381' |
5 | app.conf.broker_url = {"master_name": "cluster1"} |
6 | # 可见性超时时间,默认redis是1小时,在将消息重新发送到另一个worker之前等待worker确认的任务的秒数 |
7 | app.conf.broker_transport_options = {'visibility_timeout': 3600} |
8 | # 存储result到backend |
9 | app.conf.result_backend = 'redis://localhost:6379/0' |
10 | # backend是哨兵集群 |
11 | app.conf.result_backend = 'sentinel://localhost:26379;sentinel://localhost:26380;sentinel://localhost:26381' |
12 | app.conf.result_backend_transport_options = {'master_name': "mymaster"} |
简单应用
1 | from celery import Celery |
2 | |
3 | app = Celery('tasks', broker='amqp://rabbitadmin:rabbitadmin@localhost:5672//test') |
4 | |
5 | |
6 | def add(x,y): |
7 | return x + y |
启动celery worker server
1 | ~]# celery -A tasks worker -l info |
2 | |
3 | -------------- celery@ZGXMacBook-Pro.local v4.2.0rc4 (windowlicker) |
4 | ---- **** ----- |
5 | --- * *** * -- Darwin-17.7.0-x86_64-i386-64bit 2018-08-06 16:43:28 |
6 | -- * - **** --- |
7 | - ** ---------- [config] |
8 | - ** ---------- .> app: tasks:0x105e25390 |
9 | - ** ---------- .> transport: amqp://rabbitadmin:**@localhost:5672//test |
10 | - ** ---------- .> results: disabled:// |
11 | - *** --- * --- .> concurrency: 8 (prefork) |
12 | -- ******* ---- .> task events: OFF (enable -E to monitor tasks in this worker) |
13 | --- ***** ----- |
14 | -------------- [queues] |
15 | .> celery exchange=celery(direct) key=celery |
16 | |
17 | |
18 | [tasks] |
19 | . ce.add |
20 | |
21 | [2018-08-06 16:43:28,363: INFO/MainProcess] Connected to amqp://rabbitadmin:**@127.0.0.1:5672//test |
22 | [2018-08-06 16:43:28,375: INFO/MainProcess] mingle: searching for neighbors |
23 | [2018-08-06 16:43:29,413: INFO/MainProcess] mingle: all alone |
24 | [2018-08-06 16:43:29,428: INFO/MainProcess] celery@ZGXMacBook-Pro.local ready. |
请求celery
1 | from ce import add |
2 | |
3 | add(4,4) # local call |
4 | 8 |
5 | |
6 | add.delay(4,4) # async call |
7 | <AsyncResult: 31f0e64f-56db-496f-a666-408491776e18> |
8 | |
9 | add.delay(4,4).get() # 因为没有配置result backend,所以无法获取异步执行结果 |
10 | NotImplementedError: No result backend is configured. |
11 | Please see the documentation for more information. |
配置result backend
1 | from celery import Celery |
2 | |
3 | app = Celery('tasks', broker='amqp://rabbitadmin:rabbitadmin@localhost:5672//test',backend='redis://localhost:6379/0') |
4 | |
5 | |
6 | def add(x,y): |
7 | return x + y |
请求celery
1 | from ce import add |
2 | |
3 | add.delay(4,4).get() |
4 | 8 |
5 | |
6 | result = add.delay(4,4) |
7 | result.ready() |
8 | True |
9 | result.get(timeout=5) |
10 | 8 |
11 | result.forget() |
12 | result.get() |
13 | |
14 | result = add.delay(‘4’,4) |
15 | result.get(propagate=False) |
16 | TypeError('must be str, not int') |
17 | result.traceback # 异常追踪 |
配置
celery的默认配置可以满足大多数用例,但是也是有许多配置可以按照需求进行配置的,可以直接在应用程序设置配置,也可以使用专用的配置模块。
1 | app.config.task_serializer = 'json' |
如果需要一次配置多个配置:
1 | app.conf.update( |
2 | task_serializer='json', |
3 | accept_content='json', |
4 | result_serializer='json', |
5 | timezone='Asia/Shanghai', |
6 | ) |
对于大型项目建议直接使用专用的配置模块:
1 | app.config_from_object('celeryconfig') |
celeryconfig.py
1 | broker_url = 'amqp://rabbitadmin:rabbitadmin@localhost:5672//test' |
2 | result_backend = 'redis://localhost:6379/0' |
3 | |
4 | task_serializer='json' |
5 | accept_content='json' |
6 | result_serializer='json' |
7 | timezone='Asia/Shanghai' |
将特定的行为的任务路由到专用的队列:
1 | task_routes = { |
2 | "tasks.add": "low" |
3 | } |
限制任务执行的速率:
1 | task_annotations = { |
2 | "tasks.add": {"rate_limit": "10/m"} |
3 | } |
如果broker使用的是rabbitmq或者redis,也可以直接设置worker的速率:
1 | celery -A tasks control rate_limit ce.add 10/m |
2 | -> celery@ZGXMacBook-Pro.local: OK |
3 | new rate limit set successfully |
使用celery作为应用
1 | proj/__init__.py |
2 | /celery.py |
3 | /tasks.py |
proj/celery.py
1 | from __future__ import absolute_import, unicode_literals |
2 | from celery import Celery |
3 | |
4 | app = Celery('proj', |
5 | broker = 'amqp://rabbitadmin:rabbitadmin@localhost:5672//test', |
6 | backend = 'redis://localhost:6379/0', |
7 | include=['proj.tasks']) |
8 | |
9 | app.conf.update( |
10 | result_expires=3600, |
11 | ) |
12 | |
13 | if __name__ == "__main__": |
14 | app.start() |
proj/tasks.py
1 | from __future__ import absolute_import, unicode_literals |
2 | from .celery import app |
3 | |
4 | |
5 | def add(x, y): |
6 | return x + y |
7 | |
8 | |
9 | def mul(x, y): |
10 | return x * y |
11 | |
12 | |
13 | def xsum(numbers): |
14 | return sum(numbers) |
启动app
1 | ~]# celery -A proj worker -l info |
2 | |
3 | -------------- celery@ZGXMacBook-Pro.local v4.2.1 (windowlicker) |
4 | ---- **** ----- |
5 | --- * *** * -- Darwin-17.7.0-x86_64-i386-64bit 2018-08-06 22:27:39 |
6 | -- * - **** --- |
7 | - ** ---------- [config] |
8 | - ** ---------- .> app: proj:0x10afaf048 |
9 | - ** ---------- .> transport: amqp://rabbitadmin:**@localhost:5672//test |
10 | - ** ---------- .> results: redis://localhost:6379/0 |
11 | - *** --- * --- .> concurrency: 8 (prefork) |
12 | -- ******* ---- .> task events: OFF (enable -E to monitor tasks in this worker) |
13 | --- ***** ----- |
14 | -------------- [queues] |
15 | .> celery exchange=celery(direct) key=celery |
16 | |
17 | |
18 | [tasks] |
19 | . proj.tasks.add |
20 | . proj.tasks.mul |
21 | . proj.tasks.xsum |
22 | |
23 | [2018-08-06 22:27:40,062: INFO/MainProcess] Connected to amqp://rabbitadmin:**@127.0.0.1:5672//test |
24 | [2018-08-06 22:27:40,076: INFO/MainProcess] mingle: searching for neighbors |
25 | [2018-08-06 22:27:41,113: INFO/MainProcess] mingle: all alone |
26 | [2018-08-06 22:27:41,128: INFO/MainProcess] celery@ZGXMacBook-Pro.local ready. |
后台启动
1 | ~]# celery multi start app1 -A proj -l info |
2 | celery multi v4.2.1 (windowlicker) |
3 | > Starting nodes... |
4 | > app1@ZGXMacBook-Pro.local: OK |
5 | ~]# celery multi restart app1 -A proj -l info |
6 | ~]# celery multi stop app1 -A proj -l info |
7 | ~]# celery multi stopwait app1 -A proj -l info # 取保所有执行的tasks已完成才退出 |
注意: celery multi不存储关于worker的任何信息,所以当我们需要重启的时候相同的命令行选项,当停止的时候需要相同的pidfile和logfile,所以好的习惯是记得创建pidfile和logfile
1 | ~]# celery multi start app2 -A proj -l info --pidfile=/var/run/celery/%n.pid --logfile=/var/log/celery/%n%I.log |
multi命令提供为不同的worker指定参数的方法:
1 | ~]# celery multi start 10 -A proj -l info -Q:1-3 images,video -Q:4,5 data -Q default -L:4-5 debug |
调用task
1 | from proj import tasks |
2 | |
3 | tasks.add.delay(1,2) |
4 | tasks.add.apply_async((1,2)) |
5 | tasks.add.apply_async((1,2), queue='test', countdown=10) # 指定队列,延迟10秒后发送 |
6 | tasks.add.apply_async((2,2), link=other_task.s()) # link选项可以将前一个apply_async的执行结果,作为其他任务的arg选项签名,fork出子进程执行 |
7 | tasks.add.apply_async((2,2), link=add.s(8)) |
8 | tasks.add.apply_async((2,2), link=other_task(immutable=True)) # immutable 执行结果不采用,不可变签名 |
9 | tasks.add(1,2) # 本地调用 |
10 | |
11 | res = add.apply_async((2,2), link=add.s(10)) |
12 | res.get() |
13 | 4 |
14 | res.children[0].get() |
15 | 14 |
16 | list(res.collect()) |
17 | [(<AsyncResult: 19e1af56-9880-4696-8de4-23724e4521f8>, 4), |
18 | (<AsyncResult: 6718daf1-aaa9-4ce3-9c5a-124d829d4c54>, 14)] |
19 | |
20 | s=add.s(2,2) |
21 | s.link(mul.s(4)) |
22 | |
23 | # 错误处理 |
24 | add.s(2,2).on_error(log_error.s()).delay() |
25 | ass.apply_async((2,2), link_error=log_error.s()) |
一个任务只能在单一的状态,这个状态可以是:
1 | PENDING -> STARTED -> SUCCESS |
设计工作流
签名以一种方式封装单个任务调用的参数和执行选项,以便可以将其传递给函数,甚至序列化并通过网络发送。
1 | from proj import tasks |
2 | |
3 | s1 = tasks.add.s((2,2), countdown=10) |
4 | res = si.delay() |
5 | res.get() |
6 | 4 |
7 | |
8 | ~s1 # 等于s1.delay().get() |
9 | 4 |
10 | |
11 | # incomplete partial |
12 | s2 = tasks.add.s(2) # tasks.add(?, 2) |
13 | res = s2.delay(8) |
14 | res.get() |
15 | 10 |
- sig.apply_async(args=(), kwargs={}, **options)
- sig.delay(args, *kwargs)
Groups
1 | from celery import group |
2 | from proj.tasks import add |
3 | |
4 | group(add.s(i,i) for i in range(10))().get() |
5 | [0, 2, 4, 6, 8, 10, 12, 14, 16, 18] |
6 | |
7 | group(add.s(i,i) for i in range(10)) |
8 | group([proj.tasks.add(0, 0), add(1, 1), add(2, 2), add(3, 3), add(4, 4), add(5, 5), add(6, 6), add(7, 7), add(8, 8), add(9, 9)]) |
9 | |
10 | group(add.s(i,i) for i in range(10))() |
11 | <GroupResult: 1783520b-0b09-41cb-9fd5-924ba8c2fb66 [0ca7b0e7-5e4f-4494-aaf9-88cc73bc7e34, 58ce55c7-5d60-426b-a638-e9c8fe0232d2, c5c6741c-b4b5-4910-84d8-6e46bb8fa9e8, e26c0a3d-ff2b-41a7-b75e-6a3a9a0f86a5, 5f6f1068-0149-418f-8549-f1242ac52f6e, eaf2c00f-4861-4454-b13f-91063dbe09d4, f51526a6-4f16-44cc-8848-e30028e72f03, e66614fa-da40-4251-b223-e2c0440bb647, 6f042fca-38c7-4c8d-b8f9-db5b000f45b9, 891f9415-6c61-4900-99c0-dee7a72a5ce9]> |
12 | |
13 | # Partial group |
14 | g = group(add.s(i) for i in range(10)) |
15 | g(10).get() |
16 | [10, 11, 12, 13, 14, 15, 16, 17, 18, 19] |
Chains
1 | from celery import chain |
2 | from proj.tasks import add, mul |
3 | |
4 | # (4+4) * 8 |
5 | chain(add.s(4, 4) | mul.s(8))().get() |
6 | # (16+4)*8 |
7 | chain(add.s(4) | mul.s(8))(16).get() |
8 | # ((4+16)*2+4)*8 |
9 | chain(add.s(4,16) | mul.s(2) | (add.s(4) | mul.s(8))).delay().get() |
10 | # 不可变签名 |
11 | res = (add.si(2,2) | mul.si(5,5) | add.si(1,1)).apply_async() |
12 | res.get() |
13 | 2 |
14 | res.parent.get() |
15 | 25 |
16 | res.parent.parent.get() |
17 | 4 |
Chords
1 | from celery import chord |
2 | from proj.tasks import add,xsum |
3 | |
4 | chord((add.s(i,i) for i in range(10)), xsum.s())().get() # 当组内的任务执行完成,回调给后面的任务,前面任务返回的是一个列表 |
5 | 90 |
6 | |
7 | chord((add.s(i,i) for i in range(10)), xsum.si(10))().get() # 不可变签名,前面的回调直接忽略 |
8 | 10 |
9 | |
10 | # 错误处理 |
11 | |
12 | def on_chord_error(request, exc, traceback): |
13 | print('Task {0} raised error: {1}'.format(request.id, exc)) |
14 | |
15 | res = (group(add.s(i, i) for i in range(10)) | xsum.s().on_error(on_chord_error.s()))).delay() |
Graphs
1 | res = chain(add.s(4,4), mul.s(8), mul.s(10)).apply_async() |
2 | res.parent.parent.graph |
3 | 99adc762-a879-43d8-8941-3769678df678(2) |
4 | ef90cf6a-471b-4021-87db-03feed054916(1) |
5 | 764d630d-8183-463f-8fac-d7132acca01e(0) |
6 | ef90cf6a-471b-4021-87db-03feed054916(1) |
7 | 764d630d-8183-463f-8fac-d7132acca01e(0) |
8 | 764d630d-8183-463f-8fac-d7132acca01e(0) |
Map&Starmap
1 | add.starmap(zip(range(10), range(10))).apply_async(countdown=10).get() |
2 | # 等于 |
3 | group(add.s(i, i) for i in range(10)).apply_async(countdown=10).get() |
4 | # 或者 |
5 | ~add.starmap(zip(range(10), range(10))) |
Chunks
1 | add.chunks(zip(range(100), range(100)), 10).apply_async().get() |
2 | [[0, 2, 4, 6, 8, 10, 12, 14, 16, 18], |
3 | [20, 22, 24, 26, 28, 30, 32, 34, 36, 38], |
4 | [40, 42, 44, 46, 48, 50, 52, 54, 56, 58], |
5 | [60, 62, 64, 66, 68, 70, 72, 74, 76, 78], |
6 | [80, 82, 84, 86, 88, 90, 92, 94, 96, 98], |
7 | [100, 102, 104, 106, 108, 110, 112, 114, 116, 118], |
8 | [120, 122, 124, 126, 128, 130, 132, 134, 136, 138], |
9 | [140, 142, 144, 146, 148, 150, 152, 154, 156, 158], |
10 | [160, 162, 164, 166, 168, 170, 172, 174, 176, 178], |
11 | [180, 182, 184, 186, 188, 190, 192, 194, 196, 198]] |
12 | # 或者 |
13 | ~add.chunks(zip(range(100), range(100)), 10) |