
最近看了许多并发编程的实例,基础很重要,IO网络模型是基础知识,回来补补,常见的I/O模型好好总结下:
- 阻塞I/O(blocking I/O)
- 非阻塞I/O(noblocking I/O)
- I/O多路复用(I/O multiplexing)
- 信号驱动I/O(signal driven I/O)
- 异步I/O(asynchronous I/O)
阻塞I/O
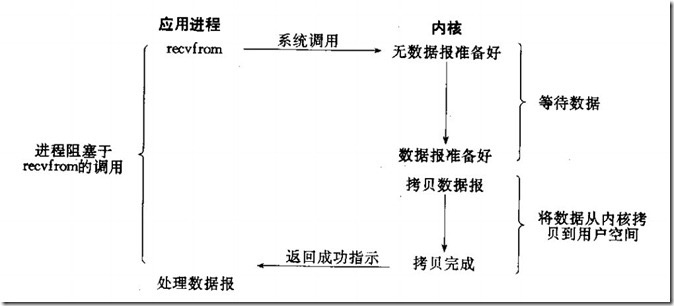
阻塞I/O是最容易理解的,linux分为内核空间和用户空间,数据的处理都是在内存中完成,阻塞I/O进程会一直等待内核空间处理完数据,进程将内核空间处理完的数据从内存中拷贝到用户空间,直到处理完全部的数据返回成功信号,这次I/O处理才是正在完成。会频繁占有cpu时钟周期。
服务端
1 | import socket |
2 | |
3 | server = socket.socket(socket.AF_INET,socket.SOCK_STREAM) |
4 | server.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1) |
5 | server.bind(('127.0.0.1',8000)) |
6 | server.listen(5) |
7 | print('Server start running...') |
8 | |
9 | while True: |
10 | conn,addr = server.accept() #IO操作,监听套接字的连接 |
11 | print('{} connected...'.format(addr[0])) |
12 | while True: |
13 | data = conn.recv(1024) #IO 操作 |
14 | if data.decode() == 'exit': |
15 | print('{} disconnect...'.format(addr[0])) |
16 | break |
17 | else: |
18 | conn.send(data.upper()) |
19 | conn.close() |
20 | else: |
21 | server.close() |
客户端
1 | import socket |
2 | |
3 | client = socket.socket(socket.AF_INET,socket.SOCK_STREAM) |
4 | client.connect(('127.0.0.1',8000)) |
5 | while True: |
6 | cmd = input('>> ').strip() |
7 | if not cmd: continue |
8 | if cmd == 'exit': |
9 | client.send(cmd.encode()) |
10 | break |
11 | else: |
12 | client.send(cmd.encode()) |
13 | data = client.recv(1024) |
14 | print('recv: {}'.format(data.decode())) |
15 | client.close() |
在阻塞I/O的模式下,使用多线程或者多进程可以让每一个连接都可以得到独立的线程或者进程,这样任何一个进程的阻塞也不会影响到其他的连接。所以这个时候会考虑使用进程池或者线程池来解决创建和销毁的频率,尽量重用已有的连接,可以很好的降低系统的开销。
非阻塞I/O
非阻塞I/O是一个轮询的过程,过一段时间进程反复询问内核准备好没数据,这个过程不阻塞进程,内核直接返回未就绪的信号,等待进程轮询下一次,直到内核空间准备好数据,返回就绪信号,进程将内核数据拷贝到用户空间。这个过程没有一直抢占着cpu时钟周期,但也是经常性占有cpu时钟周期,属于忙等的过程。
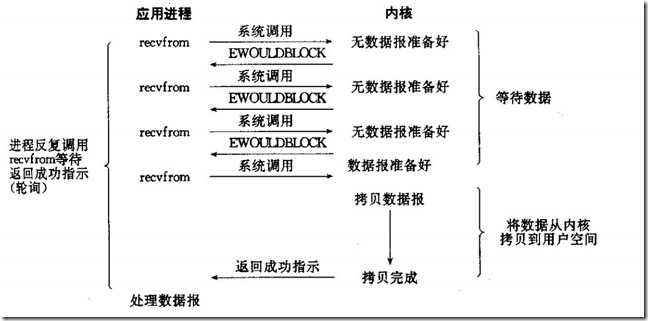
非阻塞IO中,用户进程需要不断询问kernel数据是否准备好,在python中:
1 | socket.setblocking() #默认为True,阻塞I/O |
2 | socket.setblocking(False) #改为非阻塞I/O,这只是对socket套接字来说 |
服务端
1 | import socket |
2 | import time |
3 | |
4 | server = socket.socket(socket.AF_INET,socket.SOCK_STREAM) |
5 | server.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1) |
6 | server.bind(('127.0.0.1',8000)) |
7 | server.listen(5) |
8 | server.setblocking(False) #改为非阻塞 |
9 | print('Server start running...') |
10 | conn_lst = [] |
11 | del_lst = [] |
12 | |
13 | while True: |
14 | try: |
15 | conn,addr = server.accept() #收不到套接字连接就会抛出异常 |
16 | print('{} connected...'.format(addr[0])) |
17 | conn_lst.append(conn) |
18 | except BlockingIOError: #把收不到数据的时间利用起来 |
19 | for con in conn_lst: |
20 | try: |
21 | data = con.recv(1024) |
22 | if data.decode() == 'exit': |
23 | print('{} disconnect...'.format(addr[0])) |
24 | raise ConnectionResetError |
25 | time.sleep(5) #模拟长时间应用 |
26 | conn.send(data.upper()) |
27 | except BlockingIOError: |
28 | pass |
29 | except ConnectionResetError: #连接被断开,把对象从添加到删除列表中 |
30 | del_lst.append(con) |
31 | for obj in del_lst: |
32 | obj.close() |
33 | conn_lst.remove(obj) |
34 | del_lst.clear() |
35 | else: |
36 | server.close() |
非阻塞I/O,在等待任务的时候可以完成其他工作任务,可以在同时在后台同时执行多个任务,但是轮询recv将大幅度加中cpu占用率,不适合低配主机使用,并且每过一段时间才去轮询read操作,而任务可能会在两次轮询时间的时间完成,这将会导致数据吞吐量降低。
I/O多路复用
I/O多路复用模型,就是多了一个select函数,select函数有一个文件描述符的集合,对这些文件描述符循环监听,一旦某个文件描述符就绪,就对这个文件描述符进行处理。select支持的文件描述符有限,默认为1024,这种IO模型属于阻塞I/O,但是它可以对多个文件描述符进行监听。
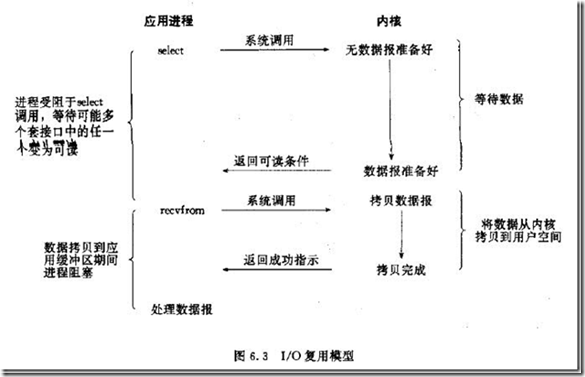
select的好处在于可以同时处理多个连接,可以看出多路复用和阻塞I/O没有多大的区别,从调用过程中可以看出调用了两次recvfrom,步骤比阻塞I/O更加繁多,所以其实可以还更加差些。
注意:
- 如果处理的连接数不是很高的话,使用select/epoll的web server不一定比使用multi-threading + blocking IO的web server性能更好,可能延迟还更大。select/epoll的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接。
- 在多路复用模型中,对于每一个socket,一般都设置成为non-blocking,但是,如上图所示,整个用户的process其实是一直被block的。只不过process是被select这个函数block,而不是被socket IO给block。
select的优势在于可以处理多个连接,不适用于单个连接
服务端
1 | import socket |
2 | import select |
3 | |
4 | server = socket.socket(socket.AF_INET,socket.SOCK_STREAM) |
5 | server.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1) |
6 | server.bind(('127.0.0.1',8000)) |
7 | server.setblocking(False) #设置非阻塞I/O |
8 | server.listen(5) |
9 | print("Server start running...") |
10 | |
11 | del_lst = [] |
12 | read_lst = [server,] |
13 | while True: |
14 | r_l,w_l,x_l = select.select(read_lst,[],[]) #select(rlist,wlist,xlist[,timeout])分别有四个参数, |
15 | print(r_l) #一开始服务端运行的时候,就等着,当客户端一链接上,这里就会有数据 |
16 | |
17 | for obj in r_l: |
18 | if obj == server: |
19 | conn,addr = obj.accept() #accept要经历两个阶段,但是程序如果走到这一步,那肯定是数据准备好了 |
20 | #当数据已经准备好的时候,accept就只经历一个copy数据的阶段了 |
21 | print('{} connected...'.format(addr[0])) |
22 | read_lst.append(conn) #再监听一个conn的套接字(这时候有两个:accept conn) |
23 | else: |
24 | try: |
25 | data = obj.recv(1024) |
26 | if data.decode() == 'exit': |
27 | print('{} disconnect...'.format(addr[0])) |
28 | raise ConnectionResetError |
29 | obj.send(data.upper()) |
30 | except ConnectionResetError: |
31 | del_lst.append(obj) |
32 | |
33 | for d in del_lst: |
34 | d.close() |
35 | read_lst.remove(d) |
36 | del_lst.clear() |
epoll/kqueue都属于select模型,那为什么epoll/kqueue比select高级,他们无论询,而是使用callback取代,给套接字注册回调函数,当套接字活跃的时候,自动完成相关操作,避免了轮询。
selectors模块可以为不同的平台选择合适的I/O多路复用模型,比如epoll在windows下就不支持。
1 | import socket |
2 | import selectors |
3 | |
4 | sel = selectors.DefaultSelector() |
5 | def accept(server,mask): |
6 | conn,addr = server.accept() |
7 | print("{} connectd...".format(addr[0])) |
8 | sel.register(conn,selectors.EVENT_READ,read) |
9 | |
10 | def read(conn,mask): |
11 | try: |
12 | data = conn.recv(1024) |
13 | if data.decode() == 'exit': |
14 | print('disconnect ...') |
15 | sel.unregister(conn) |
16 | return |
17 | conn.send(data.upper()) |
18 | except Exception: |
19 | print('closing',conn) |
20 | sel.unregister(conn) |
21 | conn.close() |
22 | |
23 | server = socket.socket(socket.AF_INET,socket.SOCK_STREAM) |
24 | server.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1) |
25 | server.bind(('127.0.0.1',8000)) |
26 | server.setblocking(False) #设置非阻塞I/O |
27 | server.listen(5) |
28 | print('Server start running...') |
29 | sel.register(server,selectors.EVENT_READ,accept) #相当于网select的读列表里append了一个文件句柄server_fileobj,并且绑定了一个回调函数accept |
30 | |
31 | while True: |
32 | events = sel.select() #检测所有的fileobj,是否有完成wait data的 |
33 | for sel_obj,mask in events: |
34 | callback = sel_obj.data #callback=accpet |
35 | callback(sel_obj.fileobj,mask) #accpet(server_fileobj,1) |
信号驱动的I/O
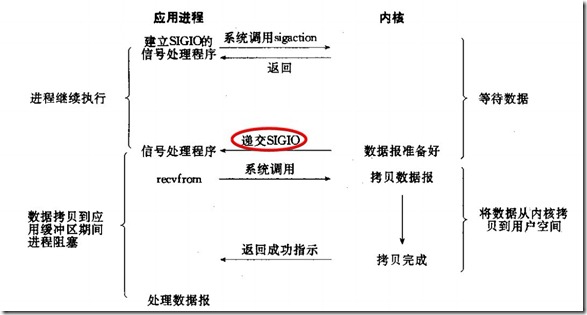
信号驱动I/O模型是应用程序告诉内核,当数据准备好的时候,给程序发一个信号,收到信号,调用信号处理函数来捕获内核数据,将这些数据拷贝到用户空间。
异步I/O
异步IO使用的不再是read和write的系统接口了,应用工程序调用aio_XXXX系列的内核接口。
当应用程序调用aio_read的时候,内核一方面去取数据报内容返回,另外一方面将程序控制权还给应用进程,应用进程继续处理其他事务。这样应用进程就是一种非阻塞的状态。
当内核的数据报就绪的时候,是由内核将数据报拷贝到应用进程中,返回给aio_read中定义好的函数处理程序。很少有linux系统支持,windows的IOCP则是此模型
完全异步的I/O复用机制,因为纵观上面其它四种模型,至少都会在由kernel copy data to appliction时阻塞。而该模型是当copy完成后才通知application,可见是纯异步的。好像只有windows的完成端口是这个模型,效率也很出色。
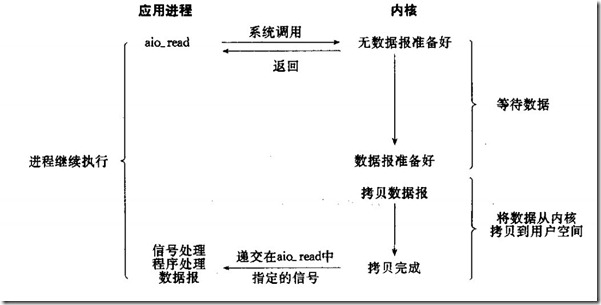
对比I/O模型
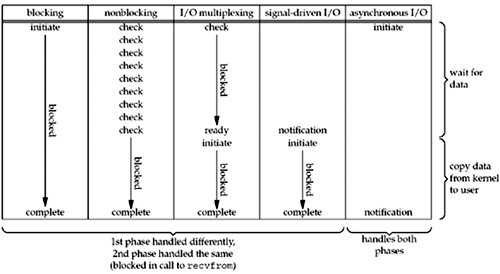
阻塞越少,性能越优秀。