
python 3
python3中内置的数据结构有5种:列表、元组、字符串、集合、字典,每种数据结构都为python带来了极大的便利,这里简单的做下总结。
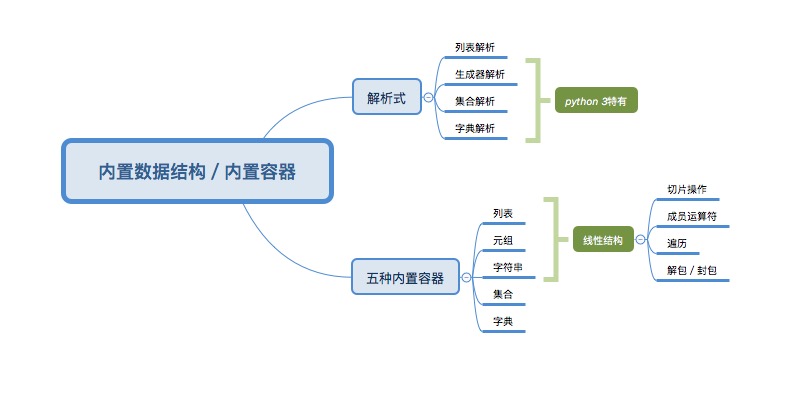
列表(list)
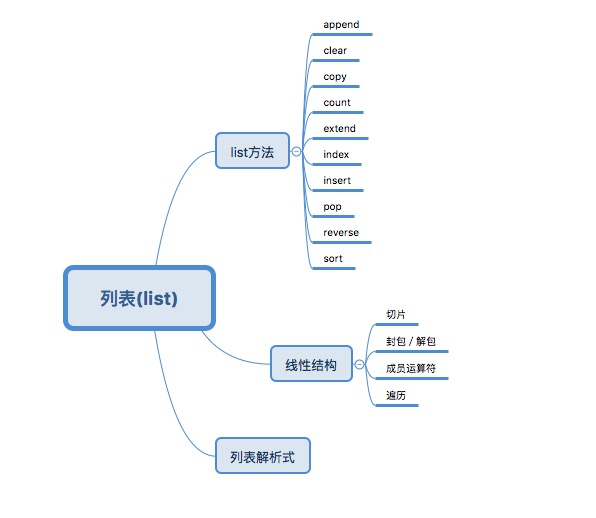
1.列表方法
1 | def append(self, p_object): # real signature unknown; restored from __doc__ |
2 | """ L.append(object) -> None -- append object to end 添加一个对象到末端""" |
3 | pass |
4 | |
5 | lst=[] |
6 | lst.append('hello') |
7 | lst.append('python') |
8 | lst |
9 | ['hello', 'python'] |
10 | |
11 | def clear(self): # real signature unknown; restored from __doc__ |
12 | """ L.clear() -> None -- remove all items from L 清空所有项目""" |
13 | pass |
14 | |
15 | lst.clear() |
16 | lst |
17 | [] |
18 | |
19 | def copy(self): # real signature unknown; restored from __doc__ |
20 | """ L.copy() -> list -- a shallow copy of L 浅拷贝""" |
21 | return [] |
22 | |
23 | lst1=lst |
24 | lst1.append('hello') |
25 | lst1.append('world') |
26 | lst1 |
27 | ['hello', 'world'] |
28 | lst |
29 | ['hello', 'world'] |
30 | id(lst) |
31 | 4458116104 |
32 | id(lst1) |
33 | 4458116104 |
34 | lst2=lst.copy() |
35 | lst2 |
36 | ['hello', 'world'] |
37 | id(lst2) |
38 | 4458049736 |
39 | lst2.clear() |
40 | lst2 |
41 | [] |
42 | lst |
43 | ['hello', 'world'] |
44 | |
45 | def count(self, value): # real signature unknown; restored from __doc__ |
46 | """ L.count(value) -> integer -- return number of occurrences of value 返回给定值的统计数量""" |
47 | return 0 |
48 | |
49 | lst=[1,1,2,3,2,0,5,6,7,4,1] |
50 | lst.count(1) |
51 | 3 |
52 | lst.count(2) |
53 | 2 |
54 | |
55 | def extend(self, iterable): # real signature unknown; restored from __doc__ |
56 | """ L.extend(iterable) -> None -- extend list by appending elements from the iterable 通过添附从iterable的要素扩大列表""" |
57 | pass |
58 | |
59 | lst |
60 | [1, 1, 2, 3, 2, 0, 5, 6, 7, 4, 1] |
61 | lst1 |
62 | ['hello', 'world'] |
63 | lst.extend(lst1) |
64 | lst |
65 | [1, 1, 2, 3, 2, 0, 5, 6, 7, 4, 1, 'hello', 'world'] |
66 | |
67 | def index(self, value, start=None, stop=None): # real signature unknown; restored from __doc__ |
68 | """ |
69 | L.index(value, [start, [stop]]) -> integer -- return first index of value. |
70 | Raises ValueError if the value is not present. 返回值的第一个索引,如果值不存在返回ValueError异常 |
71 | """ |
72 | return 0 |
73 | |
74 | lst |
75 | [1, 1, 2, 3, 2, 0, 5, 6, 7, 4, 1, 'hello', 'world'] |
76 | lst.index(2) |
77 | 2 |
78 | lst.index(3) |
79 | 3 |
80 | lst.index(0) |
81 | 5 |
82 | lst.index(0,5) |
83 | 5 |
84 | lst.index(0,1,4) |
85 | Traceback (most recent call last): |
86 | File "<stdin>", line 1, in <module> |
87 | ValueError: 0 is not in list |
88 | |
89 | def insert(self, index, p_object): # real signature unknown; restored from __doc__ |
90 | """ L.insert(index, object) -- insert object before index 在索引前插入对象""" |
91 | pass |
92 | |
93 | lst |
94 | [1, 1, 2, 3, 2, 0, 5, 6, 7, 4, 1, 'hello', 'world'] |
95 | lst.insert(2,'insert') |
96 | lst |
97 | [1, 1, 'insert', 2, 3, 2, 0, 5, 6, 7, 4, 1, 'hello', 'world'] |
98 | |
99 | def pop(self, index=None): # real signature unknown; restored from __doc__ |
100 | """ |
101 | L.pop([index]) -> item -- remove and return item at index (default last). |
102 | Raises IndexError if list is empty or index is out of range. 移除并且返回在索引的项目(默认最后),如果列表是空或者索引不在范围返回IndexError异常 |
103 | """ |
104 | pass |
105 | |
106 | lst |
107 | [1, 1, 'insert', 2, 3, 2, 0, 5, 6, 7, 4, 1, 'hello', 'world'] |
108 | lst.pop() |
109 | 'world' |
110 | lst.pop(0) |
111 | 1 |
112 | |
113 | def remove(self, value): # real signature unknown; restored from __doc__ |
114 | """ |
115 | L.remove(value) -> None -- remove first occurrence of value. |
116 | Raises ValueError if the value is not present. 移除第一个匹配的给定的值,如果值是不存在返回ValueError异常 |
117 | """ |
118 | pass |
119 | |
120 | lst |
121 | [1, 'insert', 2, 3, 2, 0, 5, 6, 7, 4, 1, 'hello'] |
122 | lst.remove('hello') |
123 | lst |
124 | [1, 'insert', 2, 3, 2, 0, 5, 6, 7, 4, 1] |
125 | |
126 | def reverse(self): # real signature unknown; restored from __doc__ |
127 | """ L.reverse() -- reverse *IN PLACE* 列表反转""" |
128 | pass |
129 | |
130 | lst |
131 | [1, 'insert', 2, 3, 2, 0, 5, 6, 7, 4, 1] |
132 | lst.reverse() |
133 | lst |
134 | [1, 4, 7, 6, 5, 0, 2, 3, 2, 'insert', 1] |
135 | |
136 | def sort(self, key=None, reverse=False): # real signature unknown; restored from __doc__ |
137 | """ L.sort(key=None, reverse=False) -> None -- stable sort *IN PLACE* 列表排序""" |
138 | pass |
139 | |
140 | lst=[1,3,5,2,6,8,3,4,2,6] |
141 | lst.sort() |
142 | lst |
143 | [1, 2, 2, 3, 3, 4, 5, 6, 6, 8] |
144 | lst.sort(reverse=True) |
145 | lst |
146 | [8, 6, 6, 5, 4, 3, 3, 2, 2, 1] |
147 | lst |
148 | ['hello', 'Python', 'love', 'World'] |
149 | lst.sort(key=str.lower) |
150 | lst |
151 | ['hello', 'love', 'Python', 'World'] #转换小写排序 |
152 | lst.sort(key=len) |
153 | lst |
154 | ['love', 'hello', 'World', 'Python'] #按照字符长短排序 |
155 | lst.sort(key=lambda string:string[1]) |
156 | lst |
157 | ['hello', 'love', 'World', 'Python'] #按照第二个字符排序 |
2.切片
python的切片总是左开右闭,从数学的可以理解为[index,index),lst[start,end,step],list可以接受三个参数。
1 | lst |
2 | [1, 3, 5, 2, 6, 8, 3, 4, 2, 6] |
3 | lst[1:4] |
4 | [3, 5, 2] |
5 | lst[2:] |
6 | [5, 2, 6, 8, 3, 4, 2, 6] |
7 | lst[-1] |
8 | 6 |
9 | lst[::2] |
10 | [1, 5, 6, 3, 2] |
11 | lst[::-1] #当step为-1的时候,切片的方向从右向左开始计算 |
12 | [6, 2, 4, 3, 8, 6, 2, 5, 3, 1] |
13 | lst[5:4:-1] |
14 | [8] |
15 | lst[-4:-5:-1] |
16 | [3] |
3.解包/封包
1 | a,[b,c],d=1,[2,3],4 |
2 | b |
3 | 2 |
4 | a,*b,c=1,2,3,3,6 |
5 | a |
6 | 1 |
7 | b |
8 | [2, 3, 3] |
9 | c |
10 | 6 |
11 | a,_,*b=1,2,3,4,5,6 |
12 | a |
13 | 1 |
14 | b |
15 | [3, 4, 5, 6] |
4.成员运算符
1 | lst |
2 | [1, 3, 5, 2, 6, 8, 3, 4, 2, 6] |
3 | 1 in lst |
4 | True |
5 | 10 in lst |
6 | False |
5.遍历
1 | for i in lst: |
2 | print(i) |
3 | |
4 | 1 |
5 | 3 |
6 | 5 |
7 | 2 |
8 | 6 |
9 | 8 |
10 | 3 |
11 | 4 |
12 | 2 |
13 | 6 |
6.列表解析式
1 | lst=[1,2,3] |
2 | lst1=[2,3,4,5] |
3 | [(x,y) for x in lst for y in lst1 ] |
4 | [(1, 2), (1, 3), (1, 4), (1, 5), (2, 2), (2, 3), (2, 4), (2, 5), (3, 2), (3, 3), (3, 4), (3, 5)] |
5 | [(x,y) for x in lst for y in lst1 if x+y > 5] |
6 | [(1, 5), (2, 4), (2, 5), (3, 3), (3, 4), (3, 5)] |
7.生成器解析式
1 | a=iter([x for x in range(10)]) |
2 | a |
3 | <list_iterator object at 0x10d0a9828> |
4 | for i in a: |
5 | print(i) |
6 | |
7 | 0 |
8 | 1 |
9 | 2 |
10 | 3 |
11 | 4 |
12 | 5 |
13 | 6 |
14 | 7 |
15 | 8 |
16 | 9 |
17 | a=iter([x for x in range(10)]) |
18 | next(a) |
19 | 0 |
20 | next(a) |
21 | 1 |
22 | next(a) |
23 | 2 |
元组(tuple)
元组与列表很相似,唯一的区别就是元组不可变。
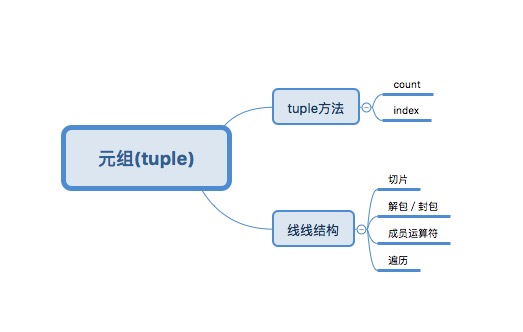
1 | a=1,2 |
2 | a |
3 | (1, 2) #python默认的数据结构是元组 |
4 | a[1]=3 |
5 | Traceback (most recent call last): |
6 | File "<stdin>", line 1, in <module> |
7 | TypeError: 'tuple' object does not support item assignment |
8 | b=3,4 |
9 | c=a+b |
10 | c |
11 | (1, 2, 3, 4) #元组是不可变的,这里的变化是重现生成了一个元组,而不是改变了元组 |
12 | d=c,b |
13 | d |
14 | ((1, 2, 3, 4), (3, 4)) |
1.元组方法
1 | def count(self, value): # real signature unknown; restored from __doc__ |
2 | """ T.count(value) -> integer -- return number of occurrences of value 返回给定值的统计数量""" |
3 | return 0 |
4 | |
5 | tup |
6 | (1, 2, 1, 2, 3, 1, 7) |
7 | tup.count(1) |
8 | 3 |
9 | |
10 | def index(self, value, start=None, stop=None): # real signature unknown; restored from __doc__ |
11 | """ |
12 | T.index(value, [start, [stop]]) -> integer -- return first index of value. |
13 | Raises ValueError if the value is not present. 返回值的第一个索引,如果值不存在返回ValueError异常 |
14 | """ |
15 | return 0 |
16 | |
17 | tup |
18 | (1, 2, 1, 2, 3, 1, 7) |
19 | tup.count(1) |
20 | 3 |
21 | tup.index(1) |
22 | 0 |
23 | tup.index(1,3) |
24 | 5 |
元组不可变所以相对的方法也少了很多,但是元组与列表相比,元组多了一个很关键的作用,元组可被hash。
其他方法属性与list相似,这里不在累赘。
字符串(str)
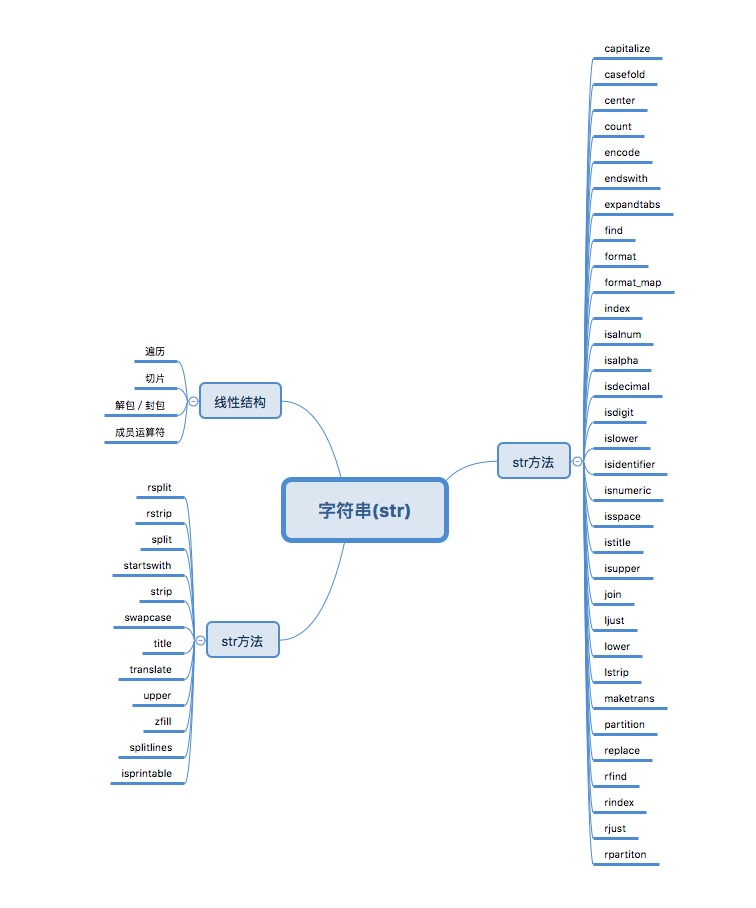
1.字符串方法
1 | def capitalize(self): # real signature unknown; restored from __doc__ |
2 | """ |
3 | S.capitalize() -> str |
4 | |
5 | Return a capitalized version of S, i.e. make the first character |
6 | have upper case and the rest lower case. 字符串的首字符大写,剩余的小写 |
7 | """ |
8 | return "" |
9 | |
10 | s='hello python' |
11 | s.capitalize() |
12 | 'Hello python' |
13 | |
14 | def casefold(self): # real signature unknown; restored from __doc__ |
15 | """ |
16 | S.casefold() -> str |
17 | |
18 | Return a version of S suitable for caseless comparisons. 返回小写字符串,针对非ASCII的一些语言里面存在小写同样适用 |
19 | """ |
20 | return "" |
21 | |
22 | su |
23 | 'HELLO PYTHON' |
24 | su.casefold() |
25 | 'hello python' |
26 | |
27 | def center(self, width, fillchar=None): # real signature unknown; restored from __doc__ |
28 | """ |
29 | S.center(width[, fillchar]) -> str |
30 | |
31 | Return S centered in a string of length width. Padding is |
32 | done using the specified fill character (default is a space) 返回一个指定长度的字符串位于中间的字符串,用指定的字符串填充(默认空格) |
33 | """ |
34 | return "" |
35 | |
36 | s.center(40) |
37 | ' hello python ' |
38 | s.center(40,'*') |
39 | '**************hello python**************' |
40 | |
41 | def count(self, sub, start=None, end=None): # real signature unknown; restored from __doc__ |
42 | """ |
43 | S.count(sub[, start[, end]]) -> int |
44 | |
45 | Return the number of non-overlapping occurrences of substring sub in |
46 | string S[start:end]. Optional arguments start and end are |
47 | interpreted as in slice notation. |
48 | """ |
49 | return 0 |
50 | |
51 | s.count('l') |
52 | 2 |
53 | s.count('l',5) |
54 | 0 |
55 | |
56 | def encode(self, encoding='utf-8', errors='strict'): # real signature unknown; restored from __doc__ |
57 | """ |
58 | S.encode(encoding='utf-8', errors='strict') -> bytes |
59 | |
60 | Encode S using the codec registered for encoding. Default encoding |
61 | is 'utf-8'. errors may be given to set a different error |
62 | handling scheme. Default is 'strict' meaning that encoding errors raise |
63 | a UnicodeEncodeError. Other possible values are 'ignore', 'replace' and |
64 | 'xmlcharrefreplace' as well as any other name registered with |
65 | codecs.register_error that can handle UnicodeEncodeErrors. 使用编码解码器解码字符串,默认utf-8, |
66 | 可以根据错误使用不同的解决方案,默认strict意味着编码错误引起一个UnicodeEncodeError,其他可以使用的还有‘ignore’,‘replace’,‘xmlcharrefreplace’可被用来处理UnicodeEncodeErrors错误。 |
67 | """ |
68 | return b"" |
69 | |
70 | s.encode() |
71 | b'hello python' 在python3中 str与bytes相互分开,默认encode将str装换为bytes |
72 | a='你好 python' |
73 | a |
74 | '你好 python' |
75 | b=a.encode() |
76 | b |
77 | b'\xe4\xbd\xa0\xe5\xa5\xbd python' |
78 | b.decode() |
79 | '你好 python' |
80 | |
81 | def endswith(self, suffix, start=None, end=None): # real signature unknown; restored from __doc__ |
82 | """ |
83 | S.endswith(suffix[, start[, end]]) -> bool |
84 | |
85 | Return True if S ends with the specified suffix, False otherwise. 返回字符串以指定前缀结尾 |
86 | With optional start, test S beginning at that position. |
87 | With optional end, stop comparing S at that position. |
88 | suffix can also be a tuple of strings to try. |
89 | """ |
90 | return False |
91 | |
92 | s |
93 | 'hello python' |
94 | s.endswith('n') |
95 | True |
96 | |
97 | def expandtabs(self, tabsize=8): # real signature unknown; restored from __doc__ |
98 | """ |
99 | S.expandtabs(tabsize=8) -> str |
100 | |
101 | Return a copy of S where all tab characters are expanded using spaces. |
102 | If tabsize is not given, a tab size of 8 characters is assumed. 把字符串中的 tab 符号('\t')转为空格,tab 符号('\t')默认的空格数是 8。 |
103 | """ |
104 | return "" |
105 | |
106 | a='hello\tpython' |
107 | a |
108 | 'hello\tpython' |
109 | print(a) |
110 | hello python |
111 | a.expandtabs() |
112 | 'hello python' |
113 | a.expandtabs(tabsize=30) |
114 | 'hello python' |
115 | |
116 | def find(self, sub, start=None, end=None): # real signature unknown; restored from __doc__ |
117 | """ |
118 | S.find(sub[, start[, end]]) -> int |
119 | |
120 | Return the lowest index in S where substring sub is found, 返回一个最小索引在字符串查找到指定的子串 |
121 | such that sub is contained within S[start:end]. Optional |
122 | arguments start and end are interpreted as in slice notation. |
123 | |
124 | Return -1 on failure. |
125 | """ |
126 | return 0 |
127 | |
128 | s |
129 | 'hello python' |
130 | s.find('h') |
131 | 0 |
132 | s.find('o') |
133 | 4 |
134 | s.find('a') |
135 | -1 #查找失败返回-1 |
136 | s.find('o',6) |
137 | 10 |
138 | |
139 | def format(self, *args, **kwargs): # known special case of str.format |
140 | """ |
141 | S.format(*args, **kwargs) -> str |
142 | |
143 | Return a formatted version of S, using substitutions from args and kwargs. 返回字符串的格式化版本 |
144 | The substitutions are identified by braces ('{' and '}'). |
145 | """ |
146 | pass |
147 | |
148 | '{}'.format('python') |
149 | 'python' |
150 | '{0} {1} {0}'.format('hello','python') |
151 | 'hello python hello' |
152 | '{name}'.format(name='python') |
153 | 'python' |
154 | a={'name':'jusene','age':23} |
155 | a |
156 | {'name': 'jusene', 'age': 23} |
157 | 'my name is {name},my age is {age}'.format(**a) |
158 | 'my name is jusene,my age is 23' |
159 | |
160 | 填充与格式化 |
161 | '{:>20}'.format('python') |
162 | ' python' |
163 | '{:<20}'.format('python') |
164 | 'python ' |
165 | '{:^20}'.format('python') |
166 | ' python ' |
167 | '{:*^20}'.format('python') |
168 | '*******python*******' |
169 | |
170 | 精度与进制 |
171 | '{:.2f}'.format(0.2222222) |
172 | '0.22' |
173 | '{:+0.2f}'.format(0.2222222) |
174 | '+0.22' |
175 | '{:+0.2f}'.format(-0.2222222) |
176 | '-0.22' |
177 | '{:0.0f}'.format(-0.5222222) |
178 | '-1' |
179 | '{:0.2%}'.format(0.5222222) |
180 | '52.22%' |
181 | '{:0.2e}'.format(0.5222222) |
182 | '5.22e-01' |
183 | '{:b}'.format(256) #二进制 |
184 | '100000000' |
185 | '{:o}'.format(256) #八进制 |
186 | '400' |
187 | '{:x}'.format(256) #16进制 |
188 | '100' |
189 | '{:,}'.format(2562442332) #千分位格式化 |
190 | '2,562,442,332' |
191 | |
192 | 叹号的用法! r s 代表str(),repr(),ascii() |
193 | '{!a}'.format('你好') |
194 | "'\\u4f60\\u597d'" |
195 | class test(object): |
196 | def __str__(self): |
197 | return('str') |
198 | def __repr__(self): |
199 | return('repr') |
200 | a=test() |
201 | '{!r}'.format(a) |
202 | 'repr' |
203 | '{!s}'.format(a) |
204 | 'str' |
205 | |
206 | def format_map(self, mapping): # real signature unknown; restored from __doc__ |
207 | """ |
208 | S.format_map(mapping) -> str |
209 | |
210 | Return a formatted version of S, using substitutions from mapping. 返回字符串的格式化版本,使用映射 |
211 | The substitutions are identified by braces ('{' and '}'). |
212 | """ |
213 | return "" |
214 | |
215 | '{name}'.format_map({'name':'zgx'}) |
216 | 'zgx' |
217 | dic={'name':['zgx','jusene'],'age':[22,25]} |
218 | 'my name is {name[1]},my age is {age[1]}'.format_map(dic) |
219 | 'my name is jusene,my age is 25' |
220 | |
221 | def index(self, sub, start=None, end=None): # real signature unknown; restored from __doc__ |
222 | """ |
223 | S.index(sub[, start[, end]]) -> int |
224 | |
225 | Return the lowest index in S where substring sub is found, 返回子串被被找到的最小索引 |
226 | such that sub is contained within S[start:end]. Optional |
227 | arguments start and end are interpreted as in slice notation. |
228 | |
229 | Raises ValueError when the substring is not found. |
230 | """ |
231 | return 0 |
232 | |
233 | s='hello python' |
234 | s.index('l',2) |
235 | 2 |
236 | s.index('l',3) |
237 | 3 |
238 | s.index('l',4) |
239 | Traceback (most recent call last): |
240 | File "<stdin>", line 1, in <module> |
241 | ValueError: substring not found |
242 | |
243 | def isalnum(self): # real signature unknown; restored from __doc__ |
244 | """ |
245 | S.isalnum() -> bool |
246 | |
247 | Return True if all characters in S are alphanumeric 如果全部的字符都是字母和数字并且至少有一个字符,返回true,否则false |
248 | and there is at least one character in S, False otherwise. |
249 | """ |
250 | return False |
251 | |
252 | s='1234qaz' |
253 | s.isalnum() |
254 | True |
255 | s='1234' |
256 | s.isalnum() |
257 | True |
258 | s='qaz' |
259 | s.isalnum() |
260 | True |
261 | s='?ss' |
262 | s.isalnum() |
263 | False |
264 | s='' |
265 | s.isalnum() |
266 | False |
267 | |
268 | def isalpha(self): # real signature unknown; restored from __doc__ |
269 | """ |
270 | S.isalpha() -> bool |
271 | |
272 | Return True if all characters in S are alphabetic 如果全部字符是字母并且至少有一个字符,返回true,否则false |
273 | and there is at least one character in S, False otherwise. |
274 | """ |
275 | return False |
276 | |
277 | s='22qw' |
278 | s.isalpha() |
279 | False |
280 | s='qwe' |
281 | s.isalpha() |
282 | True |
283 | s='123' |
284 | s.isalpha() |
285 | False |
286 | |
287 | def isdecimal(self): # real signature unknown; restored from __doc__ |
288 | """ |
289 | S.isdecimal() -> bool |
290 | |
291 | Return True if there are only decimal characters in S, 检查字符串是否只包含十进制字符,这种方法只存在于unicode对象 |
292 | False otherwise. |
293 | """ |
294 | return False |
295 | |
296 | s='1' |
297 | s.isdecimal() |
298 | True |
299 | s='1.0' |
300 | s.isdecimal() |
301 | False |
302 | s='qw' |
303 | s.isdecimal() |
304 | False |
305 | |
306 | def isdigit(self): # real signature unknown; restored from __doc__ |
307 | """ |
308 | S.isdigit() -> bool |
309 | |
310 | Return True if all characters in S are digits 如果全部字符是数字并且至少有一个字符,返回true,否则false |
311 | and there is at least one character in S, False otherwise. |
312 | """ |
313 | return False |
314 | |
315 | s='1' |
316 | s.isdigit() |
317 | True |
318 | s='1.0' |
319 | s.isdigit() |
320 | False |
321 | s='0.2' |
322 | s.isdigit() |
323 | False |
324 | s='ss11' |
325 | s.isdigit() |
326 | False |
327 | |
328 | def isidentifier(self): # real signature unknown; restored from __doc__ |
329 | """ |
330 | S.isidentifier() -> bool |
331 | |
332 | Return True if S is a valid identifier according 检测字符串是否是字母开头 |
333 | to the language definition. |
334 | |
335 | Use keyword.iskeyword() to test for reserved identifiers |
336 | such as "def" and "class". |
337 | """ |
338 | return False |
339 | |
340 | s='s12' |
341 | s.isidentifier() |
342 | True |
343 | s='1ss' |
344 | s.isidentifier() |
345 | False |
346 | |
347 | def islower(self): # real signature unknown; restored from __doc__ |
348 | """ |
349 | S.islower() -> bool |
350 | |
351 | Return True if all cased characters in S are lowercase and there is 如果全部字符是小写并且至少有一个字符,返回true,否则false |
352 | at least one cased character in S, False otherwise. |
353 | """ |
354 | return False |
355 | |
356 | s='qwe' |
357 | s.islower() |
358 | True |
359 | s='QQQ' |
360 | s.islower() |
361 | False |
362 | |
363 | def isnumeric(self): # real signature unknown; restored from __doc__ |
364 | """ |
365 | S.isnumeric() -> bool |
366 | |
367 | Return True if there are only numeric characters in S, 检测字符串是否只由数字组成。这种方法是只针对unicode对象。 |
368 | False otherwise. |
369 | """ |
370 | return False |
371 | |
372 | s='123' |
373 | s.isnumeric() |
374 | True |
375 | s='qwe' |
376 | s.isnumeric() |
377 | False |
378 | |
379 | def isprintable(self): # real signature unknown; restored from __doc__ |
380 | """ |
381 | S.isprintable() -> bool |
382 | |
383 | Return True if all characters in S are considered 判断字符串中所有字符是否都属于可见字符 |
384 | printable in repr() or S is empty, False otherwise. |
385 | """ |
386 | return False |
387 | |
388 | s='ssss\n' |
389 | s.isprintable() |
390 | False |
391 | s='ssss' |
392 | s.isprintable() |
393 | True |
394 | |
395 | def isspace(self): # real signature unknown; restored from __doc__ |
396 | """ |
397 | S.isspace() -> bool |
398 | |
399 | Return True if all characters in S are whitespace 检测字符串是否为空格 |
400 | and there is at least one character in S, False otherwise. |
401 | """ |
402 | return False |
403 | |
404 | s='' |
405 | s.isspace() |
406 | False |
407 | s=' ' |
408 | s.isspace() |
409 | True |
410 | |
411 | def istitle(self): # real signature unknown; restored from __doc__ |
412 | """ |
413 | S.istitle() -> bool |
414 | |
415 | Return True if S is a titlecased string and there is at least one 判断字符串是否适合当作标题(其实就是每个单词首字母大写) |
416 | character in S, i.e. upper- and titlecase characters may only |
417 | follow uncased characters and lowercase characters only cased ones. |
418 | Return False otherwise. |
419 | """ |
420 | return False |
421 | |
422 | s='hello python' |
423 | s.istitle() |
424 | False |
425 | s='Hello Python' |
426 | s.istitle() |
427 | True |
428 | |
429 | def isupper(self): # real signature unknown; restored from __doc__ |
430 | """ |
431 | S.isupper() -> bool |
432 | |
433 | Return True if all cased characters in S are uppercase and there is 判断字符串是否为大写 |
434 | at least one cased character in S, False otherwise. |
435 | """ |
436 | return False |
437 | |
438 | s='Hello Python' |
439 | s.isupper() |
440 | False |
441 | s='HELLO PYTHON' |
442 | s.isupper() |
443 | True |
444 | |
445 | def join(self, iterable): # real signature unknown; restored from __doc__ |
446 | """ |
447 | S.join(iterable) -> str |
448 | |
449 | Return a string which is the concatenation of the strings in the |
450 | iterable. The separator between elements is S. 用特定的分隔符连起可迭代对象成字符串 |
451 | """ |
452 | return "" |
453 | |
454 | ' '.join(['hello','python']) |
455 | 'hello python' |
456 | '-'.join('hello python'.split()) |
457 | 'hello-python' |
458 | |
459 | def ljust(self, width, fillchar=None): # real signature unknown; restored from __doc__ |
460 | """ |
461 | S.ljust(width[, fillchar]) -> str |
462 | |
463 | Return S left-justified in a Unicode string of length width. Padding is 返回以指定长度左对齐的支付串,默认以空格填充 |
464 | done using the specified fill character (default is a space). |
465 | """ |
466 | return "" |
467 | |
468 | s.ljust(20) |
469 | 'HELLO PYTHON ' |
470 | s.ljust(20,'*') |
471 | 'HELLO PYTHON********' |
472 | |
473 | def lower(self): # real signature unknown; restored from __doc__ |
474 | """ |
475 | S.lower() -> str |
476 | |
477 | Return a copy of the string S converted to lowercase. 返回小写字符 |
478 | """ |
479 | return "" |
480 | |
481 | s |
482 | 'HELLO PYTHON' |
483 | s.lower() |
484 | 'hello python' |
485 | s |
486 | 'HELLO PYTHON' |
487 | |
488 | def lstrip(self, chars=None): # real signature unknown; restored from __doc__ |
489 | """ |
490 | S.lstrip([chars]) -> str |
491 | |
492 | Return a copy of the string S with leading whitespace removed. 除去左半边的空格 |
493 | If chars is given and not None, remove characters in chars instead. |
494 | """ |
495 | return "" |
496 | |
497 | s=' hello python' |
498 | s.lstrip() |
499 | 'hello python' |
500 | s.lstrip(' he') |
501 | 'llo python' |
502 | |
503 | def maketrans(self, *args, **kwargs): # real signature unknown |
504 | """ |
505 | Return a translation table usable for str.translate(). |
506 | |
507 | If there is only one argument, it must be a dictionary mapping Unicode |
508 | ordinals (integers) or characters to Unicode ordinals, strings or None. |
509 | Character keys will be then converted to ordinals. |
510 | If there are two arguments, they must be strings of equal length, and |
511 | in the resulting dictionary, each character in x will be mapped to the |
512 | character at the same position in y. If there is a third argument, it |
513 | must be a string, whose characters will be mapped to None in the result. 用于创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。 |
514 | """ |
515 | pass |
516 | |
517 | intab |
518 | 'abcdef' |
519 | outtab |
520 | 'ABCDEF' |
521 | s.maketrans(intab,outtab) |
522 | {97: 65, 98: 66, 99: 67, 100: 68, 101: 69, 102: 70} |
523 | s='cdacdsacbnhjccdaa' |
524 | tab=s.maketrans(intab,outtab) |
525 | s.translate(tab) |
526 | 'CDACDsACBnhjCCDAA' |
527 | |
528 | def partition(self, sep): # real signature unknown; restored from __doc__ |
529 | """ |
530 | S.partition(sep) -> (head, sep, tail) |
531 | |
532 | Search for the separator sep in S, and return the part before it, |
533 | the separator itself, and the part after it. If the separator is not |
534 | found, return S and two empty strings. 根据指定的分隔符将字符串进行分割。 |
535 | 如果字符串包含指定的分隔符,则返回一个3元的元组,第一个为分隔符左边的子串,第二个为分隔符本身,第三个为分隔符右边的子串。 |
536 | """ |
537 | pass |
538 | |
539 | url='url:http://www.jusene.me' |
540 | url.partition(':') |
541 | ('url', ':', 'http://www.jusene.me') |
542 | |
543 | def replace(self, old, new, count=None): # real signature unknown; restored from __doc__ |
544 | """ |
545 | S.replace(old, new[, count]) -> str |
546 | |
547 | Return a copy of S with all occurrences of substring |
548 | old replaced by new. If the optional argument count is |
549 | given, only the first count occurrences are replaced. 把字符串中的 old(旧字符串) 替换成 new(新字符串),如果指定第三个参数max,则替换不超过 max 次。 |
550 | """ |
551 | return "" |
552 | |
553 | url.replace(':','-') |
554 | 'url-http-//www.jusene.me' |
555 | url.replace(':','-',1) |
556 | 'url-http://www.jusene.me' |
557 | |
558 | def rfind(self, sub, start=None, end=None): # real signature unknown; restored from __doc__ |
559 | """ |
560 | S.rfind(sub[, start[, end]]) -> int |
561 | |
562 | Return the highest index in S where substring sub is found, |
563 | such that sub is contained within S[start:end]. Optional |
564 | arguments start and end are interpreted as in slice notation. |
565 | |
566 | Return -1 on failure. 从右向左查找 |
567 | """ |
568 | return 0 |
569 | |
570 | url='url:http://www.jusene.me' |
571 | url.rfind(':') |
572 | 8 |
573 | url.find(':') |
574 | 3 |
575 | |
576 | def rindex(self, sub, start=None, end=None): # real signature unknown; restored from __doc__ |
577 | """ |
578 | S.rindex(sub[, start[, end]]) -> int |
579 | |
580 | Return the highest index in S where substring sub is found, 从右向左查找索引 |
581 | such that sub is contained within S[start:end]. Optional |
582 | arguments start and end are interpreted as in slice notation. |
583 | |
584 | Raises ValueError when the substring is not found. |
585 | """ |
586 | return 0 |
587 | |
588 | url.rindex(':') |
589 | 8 |
590 | url.index(':') |
591 | 3 |
592 | |
593 | def rjust(self, width, fillchar=None): # real signature unknown; restored from __doc__ |
594 | """ |
595 | S.rjust(width[, fillchar]) -> str |
596 | |
597 | Return S right-justified in a string of length width. Padding is |
598 | done using the specified fill character (default is a space). |
599 | """ 返回以指定长度右对齐的支付串,默认以空格填充 |
600 | return "" |
601 | |
602 | s='hello python' |
603 | s.rjust(20) |
604 | ' hello python' |
605 | s.rjust(20,'*') |
606 | '********hello python' |
607 | |
608 | def rpartition(self, sep): # real signature unknown; restored from __doc__ |
609 | """ |
610 | S.rpartition(sep) -> (head, sep, tail) |
611 | |
612 | Search for the separator sep in S, starting at the end of S, and return |
613 | the part before it, the separator itself, and the part after it. If the |
614 | separator is not found, return two empty strings and S. |
615 | """ 从右向左查找分隔符 |
616 | pass |
617 | |
618 | url |
619 | 'url:http://www.jusene.me' |
620 | url.rpartition(':') |
621 | ('url:http', ':', '//www.jusene.me') |
622 | |
623 | def rsplit(self, sep=None, maxsplit=-1): # real signature unknown; restored from __doc__ |
624 | """ |
625 | S.rsplit(sep=None, maxsplit=-1) -> list of strings |
626 | |
627 | Return a list of the words in S, using sep as the |
628 | delimiter string, starting at the end of the string and |
629 | working to the front. If maxsplit is given, at most maxsplit |
630 | splits are done. If sep is not specified, any whitespace string |
631 | is a separator. 从右向左分割 |
632 | """ |
633 | return [] |
634 | |
635 | url.rsplit(':') |
636 | ['url', 'http', '//www.jusene.me'] |
637 | url.rsplit(':',1) |
638 | ['url:http', '//www.jusene.me'] |
639 | |
640 | def rstrip(self, chars=None): # real signature unknown; restored from __doc__ |
641 | """ |
642 | S.rstrip([chars]) -> str |
643 | |
644 | Return a copy of the string S with trailing whitespace removed. |
645 | If chars is given and not None, remove characters in chars instead. |
646 | """ |
647 | return "" 从右向左去除 |
648 | |
649 | s='hello python ' |
650 | s.rstrip() |
651 | 'hello python' |
652 | s.rstrip('n ') |
653 | 'hello pytho' |
654 | |
655 | |
656 | def split(self, sep=None, maxsplit=-1): # real signature unknown; restored from __doc__ |
657 | """ |
658 | S.split(sep=None, maxsplit=-1) -> list of strings |
659 | |
660 | Return a list of the words in S, using sep as the |
661 | delimiter string. If maxsplit is given, at most maxsplit |
662 | splits are done. If sep is not specified or is None, any |
663 | whitespace string is a separator and empty strings are |
664 | removed from the result. 字符串分割,默认是空格 |
665 | """ |
666 | return [] |
667 | |
668 | s='hello python ' |
669 | s.split() |
670 | ['hello', 'python'] |
671 | |
672 | def splitlines(self, keepends=None): # real signature unknown; restored from __doc__ |
673 | """ |
674 | S.splitlines([keepends]) -> list of strings |
675 | |
676 | Return a list of the lines in S, breaking at line boundaries. |
677 | Line breaks are not included in the resulting list unless keepends |
678 | is given and true. 按行分割 |
679 | """ |
680 | return [] |
681 | |
682 | s=''' |
683 | hello python |
684 | hello world |
685 | ''' |
686 | s.splitlines() |
687 | ['', 'hello python', 'hello world'] |
688 | |
689 | def startswith(self, prefix, start=None, end=None): # real signature unknown; restored from __doc__ |
690 | """ |
691 | S.startswith(prefix[, start[, end]]) -> bool |
692 | |
693 | Return True if S starts with the specified prefix, False otherwise. |
694 | With optional start, test S beginning at that position. |
695 | With optional end, stop comparing S at that position. |
696 | prefix can also be a tuple of strings to try. |
697 | """ 匹配以特定的前缀开头 |
698 | return False |
699 | |
700 | s |
701 | 'hello python' |
702 | s.startswith('h') |
703 | True |
704 | s.startswith('p') |
705 | False |
706 | |
707 | def strip(self, chars=None): # real signature unknown; restored from __doc__ |
708 | """ |
709 | S.strip([chars]) -> str |
710 | |
711 | Return a copy of the string S with leading and trailing |
712 | whitespace removed. |
713 | If chars is given and not None, remove characters in chars instead. |
714 | """ |
715 | return |
716 | |
717 | s=' hello ' |
718 | s.strip() |
719 | 'hello' |
720 | s='"hello"' |
721 | s |
722 | '"hello"' |
723 | s.strip('"') |
724 | 'hello' |
725 | |
726 | def swapcase(self): # real signature unknown; restored from __doc__ |
727 | """ |
728 | S.swapcase() -> str |
729 | |
730 | Return a copy of S with uppercase characters converted to lowercase |
731 | and vice versa. 大写转小写,小写转大写 |
732 | """ |
733 | return "" |
734 | |
735 | s |
736 | 'hello python' |
737 | s.title() |
738 | 'Hello Python' |
739 | a=s.title() |
740 | s.swapcase() |
741 | 'HELLO PYTHON' |
742 | a.swapcase() |
743 | 'hELLO pYTHON' |
744 | |
745 | def title(self): # real signature unknown; restored from __doc__ |
746 | """ |
747 | S.title() -> str |
748 | |
749 | Return a titlecased version of S, i.e. words start with title case |
750 | characters, all remaining cased characters have lower case. |
751 | """ |
752 | return "" 字符串返回标题格式,即每个首字母大写 |
753 | |
754 | s |
755 | 'hello python' |
756 | s.title() |
757 | 'Hello Python' |
758 | |
759 | def translate(self, table): # real signature unknown; restored from __doc__ |
760 | """ |
761 | S.translate(table) -> str |
762 | |
763 | Return a copy of the string S in which each character has been mapped |
764 | through the given translation table. The table must implement |
765 | lookup/indexing via __getitem__, for instance a dictionary or list, |
766 | mapping Unicode ordinals to Unicode ordinals, strings, or None. If |
767 | this operation raises LookupError, the character is left untouched. |
768 | Characters mapped to None are deleted. |
769 | """ |
770 | return "" 方法根据参数table给出的表(包含 256 个字符)转换字符串的字符, 要过滤掉的字符放到 del 参数中。 |
771 | |
772 | intab |
773 | 'abcdef' |
774 | outtab |
775 | 'ABCDEF' |
776 | s.maketrans(intab,outtab) |
777 | {97: 65, 98: 66, 99: 67, 100: 68, 101: 69, 102: 70} |
778 | s='cdacdsacbnhjccdaa' |
779 | tab=s.maketrans(intab,outtab) |
780 | s.translate(tab) |
781 | 'CDACDsACBnhjCCDAA' |
782 | |
783 | def upper(self): # real signature unknown; restored from __doc__ |
784 | """ |
785 | S.upper() -> str |
786 | |
787 | Return a copy of S converted to uppercase. |
788 | """ |
789 | return "" 返回大写 |
790 | |
791 | s |
792 | 'cdacdsacbnhjccdaa' |
793 | s.upper() |
794 | 'CDACDSACBNHJCCDAA' |
795 | |
796 | def zfill(self, width): # real signature unknown; restored from __doc__ |
797 | """ |
798 | S.zfill(width) -> str |
799 | |
800 | Pad a numeric string S with zeros on the left, to fill a field |
801 | of the specified width. The string S is never truncated. |
802 | """ |
803 | return "" 使用0来填充指定长度的字符串 |
804 | |
805 | s='250' |
806 | s.zfill(30) |
807 | '000000000000000000000000000250' |
线线结构的方法就不再累赘。
集合(set && frozenset)
set:可变集合,基本功能是关系测试和消除重复元素,不可hash。
frozenset:冻结集合,与tuple一样一旦创建不可更改,可被hash。
1.集合操作符
- in:是…的成员
- not in:不是…的成员
- ==:等于
- !=:不等于
- <:是…的严格子集
- <=:是…的子集(包括非严格子集)
- ‘>’:是…的严格超集
- ‘>=’:是…的超集(包括非严格超集)
- &:交集
- |:合集
- -:差补
- ^:对称差分
2.集合方法(set)
1 | def add(self, *args, **kwargs): # real signature unknown |
2 | """ |
3 | Add an element to a set. 加一个要素到集合 |
4 | |
5 | This has no effect if the element is already present. 如果这个要素已经存在,这是没影响的。 |
6 | """ |
7 | pass |
8 | |
9 | s=1,2,3 |
10 | set(s) |
11 | {1, 2, 3} |
12 | a=set(s) |
13 | a |
14 | {1, 2, 3} |
15 | a.add(4) |
16 | a |
17 | {1, 2, 3, 4} |
18 | a.add(3) |
19 | a |
20 | {1, 2, 3, 4} 所以按照这个特性,我们可以使用集合来清洗重复项 |
21 | b=[1,2,3,2,4,2,3,5,1,3] |
22 | bs=set(b) |
23 | bs |
24 | {1, 2, 3, 4, 5} |
25 | list(bs) |
26 | [1, 2, 3, 4, 5] |
27 | |
28 | def clear(self, *args, **kwargs): # real signature unknown |
29 | """ Remove all elements from this set. """ 清除集合的所以要素 |
30 | pass |
31 | |
32 | bs |
33 | {1, 2, 3, 4, 5} |
34 | bs.clear() |
35 | bs |
36 | set() |
37 | |
38 | def copy(self, *args, **kwargs): # real signature unknown |
39 | """ Return a shallow copy of a set. """ 返回一个浅拷贝集合 |
40 | pass |
41 | |
42 | a |
43 | {1, 2, 3, 4} |
44 | b=a |
45 | b.add(5) |
46 | b |
47 | {1, 2, 3, 4, 5} |
48 | a |
49 | {1, 2, 3, 4, 5} |
50 | c=a.copy() |
51 | c.add(6) |
52 | c |
53 | {1, 2, 3, 4, 5, 6} |
54 | a |
55 | {1, 2, 3, 4, 5} |
56 | |
57 | def difference(self, *args, **kwargs): # real signature unknown |
58 | """ |
59 | Return the difference of two or more sets as a new set. 返回集合的不同要素 差集 |
60 | |
61 | (i.e. all elements that are in this set but not the others.) |
62 | """ |
63 | pass |
64 | |
65 | a |
66 | {1, 2, 3, 4, 5} |
67 | c |
68 | {1, 2, 3, 4, 5, 6} |
69 | a.difference(c) |
70 | set() |
71 | c.difference(a) |
72 | {6} |
73 | a - c |
74 | set() |
75 | c - a |
76 | {6} |
77 | |
78 | def difference_update(self, *args, **kwargs): # real signature unknown |
79 | """ Remove all elements of another set from this set. """ 差修改操作 |
80 | pass |
81 | |
82 | c |
83 | {1, 2, 3, 4, 5, 6} |
84 | a |
85 | {1, 2, 3, 4, 5} |
86 | c.difference_update(a) |
87 | c |
88 | {6} |
89 | a |
90 | {1, 2, 3, 4, 5} |
91 | c=set([1,2,4,5,6]) |
92 | c |
93 | {1, 2, 4, 5, 6} |
94 | c -= a |
95 | c |
96 | {6} |
97 | |
98 | def discard(self, *args, **kwargs): # real signature unknown |
99 | """ |
100 | Remove an element from a set if it is a member. 移除集合的指定要素 |
101 | |
102 | If the element is not a member, do nothing. |
103 | """ |
104 | pass |
105 | |
106 | a |
107 | {1, 2, 3, 4, 5} |
108 | a.discard(5) |
109 | a |
110 | {1, 2, 3, 4} |
111 | a.discard(5) |
112 | a |
113 | {1, 2, 3, 4} |
114 | |
115 | def intersection(self, *args, **kwargs): # real signature unknown |
116 | """ |
117 | Return the intersection of two sets as a new set. 交集操作 |
118 | |
119 | (i.e. all elements that are in both sets.) |
120 | """ |
121 | pass |
122 | a |
123 | {1, 2, 3, 4} |
124 | c |
125 | {1, 25} |
126 | c.intersection(a) |
127 | {1} |
128 | a.intersection(c) |
129 | {1} |
130 | a & c |
131 | {1} |
132 | |
133 | def intersection_update(self, *args, **kwargs): # real signature unknown |
134 | """ Update a set with the intersection of itself and another. """ 交集修改操作 |
135 | pass |
136 | |
137 | a |
138 | {1, 2, 3, 4} |
139 | c |
140 | {1, 25} |
141 | a.intersection_update(c) |
142 | a |
143 | {1} |
144 | a={1,2,3,4} |
145 | a &= c |
146 | a |
147 | {1} |
148 | |
149 | def isdisjoint(self, *args, **kwargs): # real signature unknown |
150 | """ Return True if two sets have a null intersection. """ 如果无交集返回true |
151 | pass |
152 | |
153 | a |
154 | {1} |
155 | c |
156 | {1, 25} |
157 | a.isdisjoint(c) |
158 | False |
159 | a={2} |
160 | a.isdisjoint(c) |
161 | True |
162 | |
163 | def issubset(self, *args, **kwargs): # real signature unknown |
164 | """ Report whether another set contains this set. """ 子集测试, |
165 | pass |
166 | |
167 | a={1,2} |
168 | b={1,2,3} |
169 | a.issubset(b) a集合的所有元素都是b集合的成员(不严格的子集测试) |
170 | True |
171 | a={1,2,4} |
172 | a.issubset(b) |
173 | False |
174 | a <= b |
175 | False |
176 | a={1,2} |
177 | a <= b |
178 | True |
179 | |
180 | a 严格子集测试,a!=b并且a的元素都是b的元素 |
181 | {1, 2} |
182 | b |
183 | {1, 2, 3} |
184 | a<b |
185 | True |
186 | a={1,2,3} |
187 | a<b |
188 | False |
189 | a<=b |
190 | True |
191 | |
192 | def issuperset(self, *args, **kwargs): # real signature unknown |
193 | """ Report whether this set contains another set. """ 超集测试 |
194 | pass |
195 | |
196 | a |
197 | {1, 2, 3, 4} |
198 | b |
199 | {1, 2, 3} |
200 | a.issuperset(b) a集合的元素包含了b集合的成员(不严格的超集测试) |
201 | True |
202 | a>=b |
203 | True |
204 | |
205 | b={1,2,3,4} 严格超集测试,a!=b并且a的元素包含b的元素 |
206 | a>b |
207 | False |
208 | a>=b |
209 | True |
210 | |
211 | def pop(self, *args, **kwargs): # real signature unknown |
212 | """ |
213 | Remove and return an arbitrary set element. |
214 | Raises KeyError if the set is empty. |
215 | """ |
216 | pass |
217 | |
218 | a |
219 | {1, 2, 3, 4} |
220 | a.pop() |
221 | 1 |
222 | a.pop() |
223 | 2 |
224 | a.pop() |
225 | 3 |
226 | a.pop() |
227 | 4 |
228 | a.pop() |
229 | Traceback (most recent call last): |
230 | File "<stdin>", line 1, in <module> |
231 | KeyError: 'pop from an empty set' |
232 | a={1,2,3,4} |
233 | a.pop(-1) |
234 | Traceback (most recent call last): |
235 | File "<stdin>", line 1, in <module> |
236 | TypeError: pop() takes no arguments (1 given) |
237 | |
238 | def remove(self, *args, **kwargs): # real signature unknown |
239 | """ |
240 | Remove an element from a set; it must be a member. |
241 | |
242 | If the element is not a member, raise a KeyError. |
243 | """ |
244 | pass |
245 | |
246 | a |
247 | {1, 2, 3, 4} |
248 | a.remove(1) |
249 | a.remove(5) |
250 | Traceback (most recent call last): |
251 | File "<stdin>", line 1, in <module> |
252 | KeyError: 5 |
253 | |
254 | def symmetric_difference(self, *args, **kwargs): # real signature unknown |
255 | """ |
256 | Return the symmetric difference of two sets as a new set. 对称差分 |
257 | |
258 | (i.e. all elements that are in exactly one of the sets.) |
259 | """ |
260 | pass |
261 | |
262 | a |
263 | {2, 3, 4} |
264 | b |
265 | {1, 2, 3, 4} |
266 | a.symmetric_difference(b) a和b的元素,但不是a和b公用的元素 |
267 | {1} |
268 | b.symmetric_difference(a) |
269 | {1} |
270 | a^b |
271 | {1} |
272 | |
273 | def symmetric_difference_update(self, *args, **kwargs): # real signature unknown |
274 | """ Update a set with the symmetric difference of itself and another. """ 对称差分操作 |
275 | pass |
276 | |
277 | a |
278 | {2, 3, 4} |
279 | b |
280 | {1, 2, 3, 4} |
281 | a.symmetric_difference_update(b) |
282 | a |
283 | {1} |
284 | a={2,3,4} |
285 | a^=b |
286 | a |
287 | {1} |
288 | |
289 | def union(self, *args, **kwargs): # real signature unknown |
290 | """ |
291 | Return the union of sets as a new set. 合并操作 |
292 | |
293 | (i.e. all elements that are in either set.) |
294 | """ |
295 | pass |
296 | |
297 | a={1,2,3} |
298 | b={2,3,4} |
299 | a.union(b) |
300 | {1, 2, 3, 4} |
301 | a|b |
302 | {1, 2, 3, 4} |
303 | |
304 | def update(self, *args, **kwargs): # real signature unknown |
305 | """ Update a set with the union of itself and others. """ 合并修改操作 |
306 | pass |
307 | |
308 | a={1,2,3} |
309 | b={2,3,4} |
310 | a.update(b) |
311 | a |
312 | {1, 2, 3, 4} |
313 | a={1,2,3} |
314 | a|=b |
315 | a |
316 | {1, 2, 3, 4} |
3.集合方法(frozenset)
1 | def copy(self, *args, **kwargs): # real signature unknown |
2 | """ Return a shallow copy of a set. """ |
3 | pass |
4 | |
5 | a=frozenset([1,2,3]) |
6 | a |
7 | frozenset({1, 2, 3}) |
8 | b=a.copy() |
9 | id(a) |
10 | 4513784104 |
11 | id(b) |
12 | 4513784104 |
13 | |
14 | def difference(self, *args, **kwargs): # real signature unknown |
15 | """ |
16 | Return the difference of two or more sets as a new set. |
17 | |
18 | (i.e. all elements that are in this set but not the others.) |
19 | """ |
20 | pass |
21 | |
22 | a |
23 | frozenset({1, 2, 3}) |
24 | b=frozenset([1,2,3,4]) |
25 | a |
26 | frozenset({1, 2, 3}) |
27 | b |
28 | frozenset({1, 2, 3, 4}) |
29 | a.difference(b) |
30 | frozenset() |
31 | b.difference(a) |
32 | frozenset({4}) |
33 | |
34 | def intersection(self, *args, **kwargs): # real signature unknown |
35 | """ |
36 | Return the intersection of two sets as a new set. |
37 | |
38 | (i.e. all elements that are in both sets.) |
39 | """ |
40 | pass |
41 | |
42 | a.intersection(b) |
43 | frozenset({1, 2, 3}) |
44 | a&b |
45 | frozenset({1, 2, 3}) |
46 | |
47 | def isdisjoint(self, *args, **kwargs): # real signature unknown |
48 | """ Return True if two sets have a null intersection. """ |
49 | pass |
50 | |
51 | a.isdisjoint(b) |
52 | False |
53 | |
54 | def issubset(self, *args, **kwargs): # real signature unknown |
55 | """ Report whether another set contains this set. """ |
56 | pass |
57 | |
58 | a.issubset(b) |
59 | True |
60 | a<b |
61 | True |
62 | a<=b |
63 | True |
64 | |
65 | |
66 | def issuperset(self, *args, **kwargs): # real signature unknown |
67 | """ Report whether this set contains another set. """ |
68 | pass |
69 | |
70 | b.issuperset(a) |
71 | True |
72 | b>a |
73 | True |
74 | b>=a |
75 | True |
76 | |
77 | |
78 | def symmetric_difference(self, *args, **kwargs): # real signature unknown |
79 | """ |
80 | Return the symmetric difference of two sets as a new set. |
81 | |
82 | (i.e. all elements that are in exactly one of the sets.) |
83 | """ |
84 | pass |
85 | |
86 | a.symmetric_difference(b) |
87 | frozenset({4}) |
88 | |
89 | def union(self, *args, **kwargs): # real signature unknown |
90 | """ |
91 | Return the union of sets as a new set. |
92 | |
93 | (i.e. all elements that are in either set.) |
94 | """ |
95 | pass |
96 | |
97 | a.union(b) |
98 | frozenset({1, 2, 3, 4}) |
4.集合表达式
1 | set(x for x in range(10)) |
2 | {0, 1, 2, 3, 4, 5, 6, 7, 8, 9} |
- 生成器表达式
1 | iter(set(x for x in range(10))) |
2 | <set_iterator object at 0x10d0ac288> |
3 | a=iter(set(x for x in range(10))) |
4 | next(a) |
5 | 0 |
6 | next(a) |
7 | 1 |
8 | next(a) |
9 | 2 |
10 | >>> |
5.成员运算符
1 | a=set([x for x in range(10)]) |
2 | a |
3 | {0, 1, 2, 3, 4, 5, 6, 7, 8, 9} |
4 | 1 in a |
5 | True |
字典(dict)
1.字典方法
1 | def clear(self): # real signature unknown; restored from __doc__ |
2 | """ D.clear() -> None. Remove all items from D. """ 清除字典的所有元素 |
3 | pass |
4 | |
5 | d=dict() |
6 | d[1]='a' |
7 | d[2]='b' |
8 | d |
9 | {1: 'a', 2: 'b'} |
10 | d.clear() |
11 | d |
12 | {} |
13 | |
14 | def copy(self): # real signature unknown; restored from __doc__ |
15 | """ D.copy() -> a shallow copy of D """ 浅拷贝 |
16 | pass |
17 | |
18 | dc=d.copy() |
19 | a=d |
20 | id(dc) |
21 | 4513775976 |
22 | id(a) |
23 | 4513776264 |
24 | id(d) |
25 | 4513776264 |
26 | |
27 | def fromkeys(*args, **kwargs): # real signature unknown |
28 | """ Returns a new dict with keys from iterable and values equal to value. """ 从一个可迭代对象作为键和自定义值(默认None)的新字典 |
29 | pass |
30 | |
31 | a=1,2,3 |
32 | d.fromkeys(a) |
33 | {1: None, 2: None, 3: None} |
34 | d.fromkeys(a,10) |
35 | {1: 10, 2: 10, 3: 10} |
36 | |
37 | def get(self, k, d=None): # real signature unknown; restored from __doc__ |
38 | """ D.get(k[,d]) -> D[k] if k in D, else d. d defaults to None. """ 如果指定的键在字典中,返回值,如果不存在默认返回None,可以指定非字典键返回的值 |
39 | pass |
40 | |
41 | d={'a':1,'b':2} |
42 | d.get('a') |
43 | 1 |
44 | d.get('c') |
45 | d.get('c',100) |
46 | 100 |
47 | |
48 | def items(self): # real signature unknown; restored from __doc__ |
49 | """ D.items() -> a set-like object providing a view on D's items """ |
50 | pass |
51 | |
52 | d |
53 | {'a': 1, 'b': 2} |
54 | d.items() |
55 | dict_items([('a', 1), ('b', 2)]) |
56 | for k,v in d.items(): |
57 | print(k,v) |
58 | |
59 | a 1 |
60 | b 2 |
61 | |
62 | def keys(self): # real signature unknown; restored from __doc__ |
63 | """ D.keys() -> a set-like object providing a view on D's keys """ |
64 | pass |
65 | |
66 | d |
67 | {'a': 1, 'b': 2} |
68 | d.keys() |
69 | dict_keys(['a', 'b']) |
70 | for i in d.keys(): |
71 | print(i) |
72 | |
73 | a |
74 | b |
75 | |
76 | def pop(self, k, d=None): # real signature unknown; restored from __doc__ |
77 | """ |
78 | D.pop(k[,d]) -> v, remove specified key and return the corresponding value. |
79 | If key is not found, d is returned if given, otherwise KeyError is raised 移除指定键的键对值,返回值,如果键没被发现,值如果被给则返回,否则KeyError |
80 | """ |
81 | pass |
82 | |
83 | d |
84 | {'a': 1, 'b': 2} |
85 | d.pop('a') |
86 | 1 |
87 | d.pop('c') |
88 | Traceback (most recent call last): |
89 | File "<stdin>", line 1, in <module> |
90 | KeyError: 'c' |
91 | d.pop('c','None') |
92 | 'None' |
93 | |
94 | def popitem(self): # real signature unknown; restored from __doc__ |
95 | """ |
96 | D.popitem() -> (k, v), remove and return some (key, value) pair as a 移除并且以2个元组的形式返回键对值 |
97 | 2-tuple; but raise KeyError if D is empty. |
98 | """ |
99 | |
100 | d.popitem() |
101 | ('b', 2) |
102 | d.popitem() |
103 | Traceback (most recent call last): |
104 | File "<stdin>", line 1, in <module> |
105 | KeyError: 'popitem(): dictionary is empty' |
106 | |
107 | def setdefault(self, k, d=None): # real signature unknown; restored from __doc__ |
108 | """ D.setdefault(k[,d]) -> D.get(k,d), also set D[k]=d if k not in D """ 如果键不是字典的键,设置默认值并且加入到字典中 |
109 | pass |
110 | |
111 | d={'a':1,'b':2} |
112 | d.setdefault('a') |
113 | 1 |
114 | d.setdefault('c') |
115 | d |
116 | {'a': 1, 'b': 2, 'c': None} |
117 | d.setdefault('d',3) |
118 | 3 |
119 | d |
120 | {'a': 1, 'b': 2, 'c': None, 'd': 3} |
121 | |
122 | def update(self, E=None, **F): # known special case of dict.update |
123 | """ |
124 | D.update([E, ]**F) -> None. Update D from dict/iterable E and F. |
125 | If E is present and has a .keys() method, then does: for k in E: D[k] = E[k] |
126 | If E is present and lacks a .keys() method, then does: for k, v in E: D[k] = v |
127 | In either case, this is followed by: for k in F: D[k] = F[k] |
128 | """ |
129 | pass |
130 | d |
131 | {'a': 1, 'b': 2, 'c': None, 'd': 3} |
132 | c={} |
133 | c.update(d) |
134 | c |
135 | {'a': 1, 'b': 2, 'c': None, 'd': 3} |
136 | |
137 | def values(self): # real signature unknown; restored from __doc__ |
138 | """ D.values() -> an object providing a view on D's values """ |
139 | pass |
140 | |
141 | c |
142 | {'a': 1, 'b': 2, 'c': None, 'd': 3} |
143 | c.values() |
144 | dict_values([1, 2, None, 3]) |
145 | for i in c.values(): |
146 | print(i) |
147 | |
148 | 1 |
149 | 2 |
150 | None |
151 | 3 |
2.字典解析式
1 | {x:8 for x in range(10) if x > 6} |
2 | {7: 8, 8: 8, 9: 8} |
1 | dic={'ip':'10.0.0.2','port':80} |
2 | 'ip is {ip},port is {port}'.format(**dic) |
3 | 'ip is 10.0.0.2,port is 80' |
3.成员元算符
1 | d |
2 | {'a': 1, 'b': 2, 'c': None, 'd': 3} |
3 | |
4 | 'a' in d |
5 | True |
6 | 1 in d |
7 | False |
8 | 1 in d.values() |
9 | True |