
Mariadb or MySQL
在全世界都在去IOE的情况下,开源的力量正在不断崛起,而如今以前的开源MySQL公司被开源公敌Oracle收购,虽然目前仍是开源,但是万一哪天闭源,全世界不知道多少系统将陷入瘫痪的状态,而时事造英雄MySQL原开发人员集合开源力量,重新造就了MySQL的另一个分支Mariadb,就现实而言,一线互联网公司,阿里巴巴,facebook等都在转向Mariadb, 而CentOS7原生支持mysql也改变支持了Mariadb, Mariadb正在像一股洪流改变着MySQL的历史走向。
MySQL
虽然Mariadb正在崛起,但目前主流还是MySQL,MySQL采用了c/s架构设计,整个mysql属于三层模型:
- 物理层
- 逻辑层
- 视图层
MySQL属于关系型数据库,关系模型是由表(行,列)组成的二维关系结构,真哥哥数据最核心的是表,索引,视图。
可以操作数据库的语句叫做SQL(Structure Query Language),sql语句分为三类:
- DML:数据库操作语言
insert replace update delete … - DDL:数据定义语言
create alter drop … - DCL:数据库控制语言
grant revoke …
除此之外,mysql还提供了编程接口:
- 存储过程:Procedure
- 函数:Function
- 触发器:Trigger
- 时间调度器:event schduler
- 过程式编程:选择 循环
MySQL查询缓存
select语句执行流程:
FROM Clause –> WHERE Clause –> GROUP BY –> HAVING Clause –> ORDER BY –> SELECT –> LIMIT
select的选项:
distinct:去重
sql_cache:显式指定存储查询结果于缓存中
sql_no_cache:显示查询结果不予缓存
1 | MariaDB [db]> show global variables like "query%"; |
2 | +------------------------------+---------+ |
3 | | Variable_name | Value | |
4 | +------------------------------+---------+ |
5 | | query_alloc_block_size | 16384 | |
6 | | query_cache_limit | 1048576 | |
7 | | query_cache_min_res_unit | 4096 | |
8 | | query_cache_size | 1048576 | |
9 | | query_cache_strip_comments | OFF | |
10 | | query_cache_type | OFF | |
11 | | query_cache_wlock_invalidate | OFF | |
12 | | query_prealloc_size | 24576 | |
13 | +------------------------------+---------+ |
14 | 8 rows in set (0.00 sec) |
- query_cache_type:ON OFF DEMAND
- query_cache_type的值为ON时,查询缓存功能打开,select的结果符合缓存条件即会缓存,否则不予缓存,显示指定sql_no_cache,不予缓存
- query_cache_type的值为DEMAND时,查询缓存功能按需进行,显式指定sql_cache的select语句才会缓存,其他不予缓存
- query_cache_min_res_unit:查询缓存中内存块的最小分配单位,较小值会减少浪费,但会导致更频繁的内存分配操作,较大值会带来浪费,会导致碎片过多
- query_cache_limit:能够缓存的最大查询结果,对于有着较大结果的查询语句,建议在select中使用sql_no_cache
- query_cache_size:查询缓存总共可用的内存空间,单位是字节,必须是1024的整数倍
- query_cache_wlock_invalidate:如果某表被其他的连接锁定,是否仍然可以从查询缓存中返回结果,默认值为OFF,表示可以在表被其他连接锁定的场景中继续从缓存返回数据,ON则表示不允许。
查询是否会被命中:
通过查询语句的hash值判断,hash值考虑的因素有:
- 查询本身
- 要查询的数据表
- 客户端使用的协议版本
…
查询上的任何字符的不同,都会导致缓存不命中
哪些查询应该不被命中:
查询中包含UDF、存储函数、用户自定义变量、临时表、mysql库中的系统表,或者包含列表权限的表、有着不确定值的函数(now());
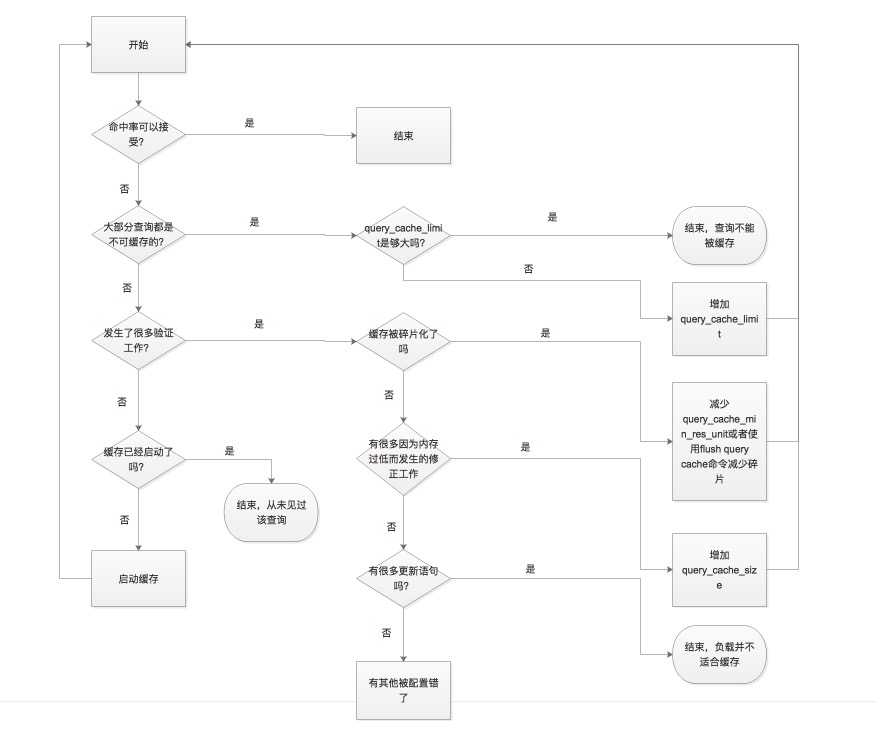
以上时缓存的排查思路。
查询缓存状态:
1 | MariaDB [db]> show global status like "Qcache%"; |
2 | +-------------------------+---------+ |
3 | | Variable_name | Value | |
4 | +-------------------------+---------+ |
5 | | Qcache_free_blocks | 1 | |
6 | | Qcache_free_memory | 1031336 | |
7 | | Qcache_hits | 0 | |
8 | | Qcache_inserts | 0 | |
9 | | Qcache_lowmem_prunes | 0 | |
10 | | Qcache_not_cached | 0 | |
11 | | Qcache_queries_in_cache | 0 | |
12 | | Qcache_total_blocks | 1 | |
13 | +-------------------------+---------+ |
缓存命中率评估:Qcache_hits/(Qcache_hits+Com_select)
存储引擎
在mysql中最应该提到的是innodb和myisam存储引擎:
- innodb
innodb支持事务,数据存储在表空间中,默认所有的数据和索引都存储在同一个表空间,表空间文件在datadir下的ibdata1,ibdata2,默认2个文件为1组,但是这样的数据导出时将会非常麻烦,所以在启用innodb宰割配置选项必须得启用,innodb_file_per_table即每个表单独使用一个表空间存储数据和索引,其他还有数据文件tb1_name.ibd和表格式定义tb1_name.frm,在Mariadb中innodb是Percona-XtraDB。 - myisam
myisam不支持事务,支持全文索引,奔溃后无法安全恢复,但是可以修复,修复时间按照表大小,适合读多写少的场景,其中tb1_name.frm定义表格式,tb1_name.MYD是数据文件,tb1_name.MYI是索引文件。
其他的存储引擎:
CSV:将普通的csv文件(字段基于逗号分隔)作为mysql表使用
MRG_MYISAM:有多个MyISAM表合并形成的虚拟表
BLACKHOLE:类似于/dev/null,不真正存储数据
MEMORY:基于内存存储,支持hash索引,表级锁,常用于临时表
PERFORMANCE_SCHEME: mysql内部状态表
ARCHIVE:只支持SELECT和INSERT操作,支持行级锁
FEDERATED: 用于访问其他的远程的mysql server的代理接口,它通过创建一个远程mysql server的客户端连接,并将查询语句传输到远程服务器执行
mysql事务
事务:一组原子性的sql查询,或者多个sql语句组成了一个独立的工作单元
满足事务需要满足ACID测试:
- A:原子性:整个事务中的所有操作要么全部成功执行,要么全部失败回滚
- C:一致性:数据库总是从一个一致性转换为另一个一致性状态
- I:隔离性:一个事务所做出的操作在提交之前,是不是为其它事务所见,隔离有多种级别,主要为了并发
- D:持久性:事务一旦提交,其所做的修改会永久保存于数据库中
事务:
- 启动事务:
1start transaction - 结束事务:事务支持savepoint
1(1)完成,提交commit2(2)未完成,回滚rollback1savepoint identifier2rollback to [savepoint] identifer3release savepoint identifier
默认事务自动提交的:
1 | show global variavles like '%commint%'; |
事务的隔离级别:
1 | read uncommitted(读未提交)-->脏读 能够读到别人未提交的数据,隔离性差 |
2 | read committed(读提交)-->不可重复读 别人提交的数据在别的事务中能够看见 |
3 | repeatable read(可重复读)-->幻读 两边的事务都提交了,才能看见修改的内容,默认隔离级别 |
4 | seriablizable(可串联) 两个事务,一个事务需要等待另一个事务的修改数据提交才能查询,否则堵塞 |
可以通过以下命令来查看事务隔离级别:
1 | show variables like 'tx_iso%'; |
MVCC
MVCC多版本并发控制,并发控制依赖的技术手段:
- 锁
- 时间戳
- 多版本和快照隔离
锁:
读锁:共享锁,可以读不可写
写锁:独占锁,不可读不可写
1 | (1)lock table |
2 | lock table tb_name [read|write] |
3 | (2)flush tables |
4 | flush tables tb_name [with read lock] |
5 | (3)select |
6 | select clause [with read lock] |
MySQL中的索引
基本法则:索引应该构建在被用作查询条件的字段上
索引类型:
1B+ Tree索引:顺序存储,每一个叶子结点到根节点的距离是相同的:左前缀索引,适合查询范围类的数据23可以使用B-Tree索引的查询类型:全键值、键值范围或键前缀查找:4全值匹配:精确某个值5匹配最左前缀:只精确匹配起头部分6匹配范围值:7精确匹配某一列并范围匹配另一列8只访问索引的查询910不适合使用B-Tree索引的场景:11如果不从最左列开始,索引无效(Age,Name)12不能跳过索引中的列(StuID,Name,Age)13如果查询中某个列是为范围查询,那么其右侧的列都无法再使用索引优化查询:(StuID,Name)Hash索引:基于哈希表实现,特别适合于精确匹配索引中的所有列
注意:只有memory存储引擎支持显式hash索引1适合场景:2只支持等值比较查询,包括= IN() <=>;34不适合使用hash索引的场景:5存储的非为值的顺序,因此,不适用于顺序查询6不支持模糊匹配空间索引(R-Tree):
MyISAM支持空间索引:全文索引(FULLTEXT):
在文本中查找关键词:
索引优点:
- 索引可以降低服务需要扫描的数据量,减少了io次数
- 索引可以帮助服务器避免排序和使用临时表
- 索引可以帮助将随机io转换成顺序io
高性能索引策略:
1 | 要使用独立的列,尽量避免其参与于运算: |
2 | 左前缀索引:索引构建于字段的左侧的多少个字符,要通过索引选择性来评估 |
3 | 索引选择性:不重复的索引值和数据表的记录总数的比值 |
4 | 多列索引: |
5 | and操作时更适合使用多列索引 |
6 | 选择合适的索引列次序,将选择性最高放在左侧 |
冗余和重复索引:
不好的索引使用策略
(Name),(Name,Age)B-Tree索引将会重复索引
通过explain来分析索引的有效性:
explain select clause
获取查询执行计划信息,用来查看优化器如何执行查询
输出:
id:当前查询语句中,每个select语句的编号
复杂类型的查询有三种:
简单子查询
用于from中的子查询
联合查询:union注意:union查询的分析结果会出现一外额外匿名临时表select_type:
简单查询为simple
复杂查询:
subquery:简单子查询
derived:用于from中的子查询
union: union语句的第一个之后的select语句
union result: 临时匿名表table: select语句关联到的表
type:关联类型,或访问类型,即mysql决定的如何去查询表中的行的方式
ALL:全表扫描
Index:根据索引的次序进行全表扫描,如果在Extra列出现“using index”表示了使用覆盖索引,而非全表扫描。
range:有范围限制的根据索引实现范围扫描:扫描位置始于索引中的某一点,结束于另一点
ref:返回表中所有匹配某个值的所有行
eq_ref:仅返回一个行,但与需要额外于某个参考值做比较
const,system:只返回当个行possible_keys:查询可能会用到的索引
key:查询中使用了的索引
key_len:在索引使用的字节数
ref:在利用key字段所表示的索引完成查询时所有的列或某常量值
rows:MySQL估计为所有的目标行而需要读取的行数
Extra:额外信息
Using index: MySQL将会使用覆盖索引,以避免访问表
Using where: MySQL服务器将在存储检索后,再进行一次过滤
Using temporary: MySQL对结果排序时会使用临时表
Using filesort: 对结果使用一个外部索引排序