
内核参数
Linux秉承一切皆文件的思想,我们可以直接修改/proc或/sys下的文件直接修改内核参数,系统内核优化千变万化,可能会因一个参数性能得到质的飞跃,也可能直接无解的服务宕机,所以别随意修改,除非你知道自己在干什么。
tcp 有限状态机
================================================================
这里会提及到TCP的有限状态机,为了可以更好理解系统调优的原理,温习下TCP的有限状态机。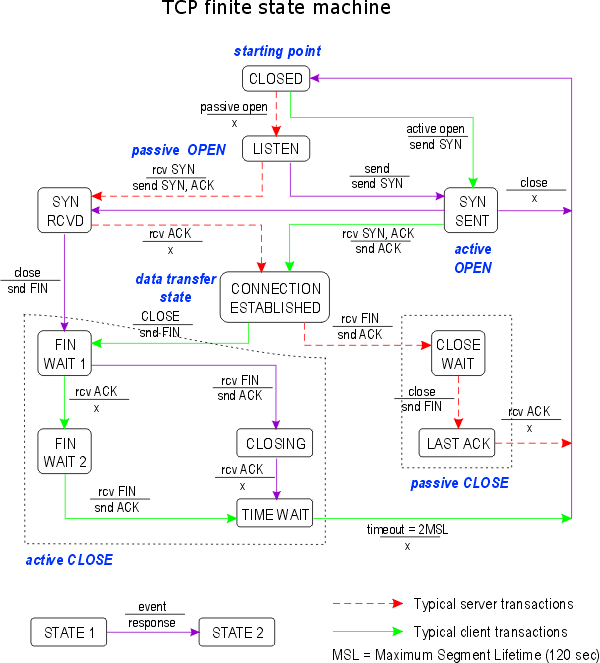
分析过程:
- 接收请求状态
服务器:closed—>listen—>syn rcve—>connection established
客户端:closed—>syn sent—>connection established
整个过程可以理解为TCP三次握手: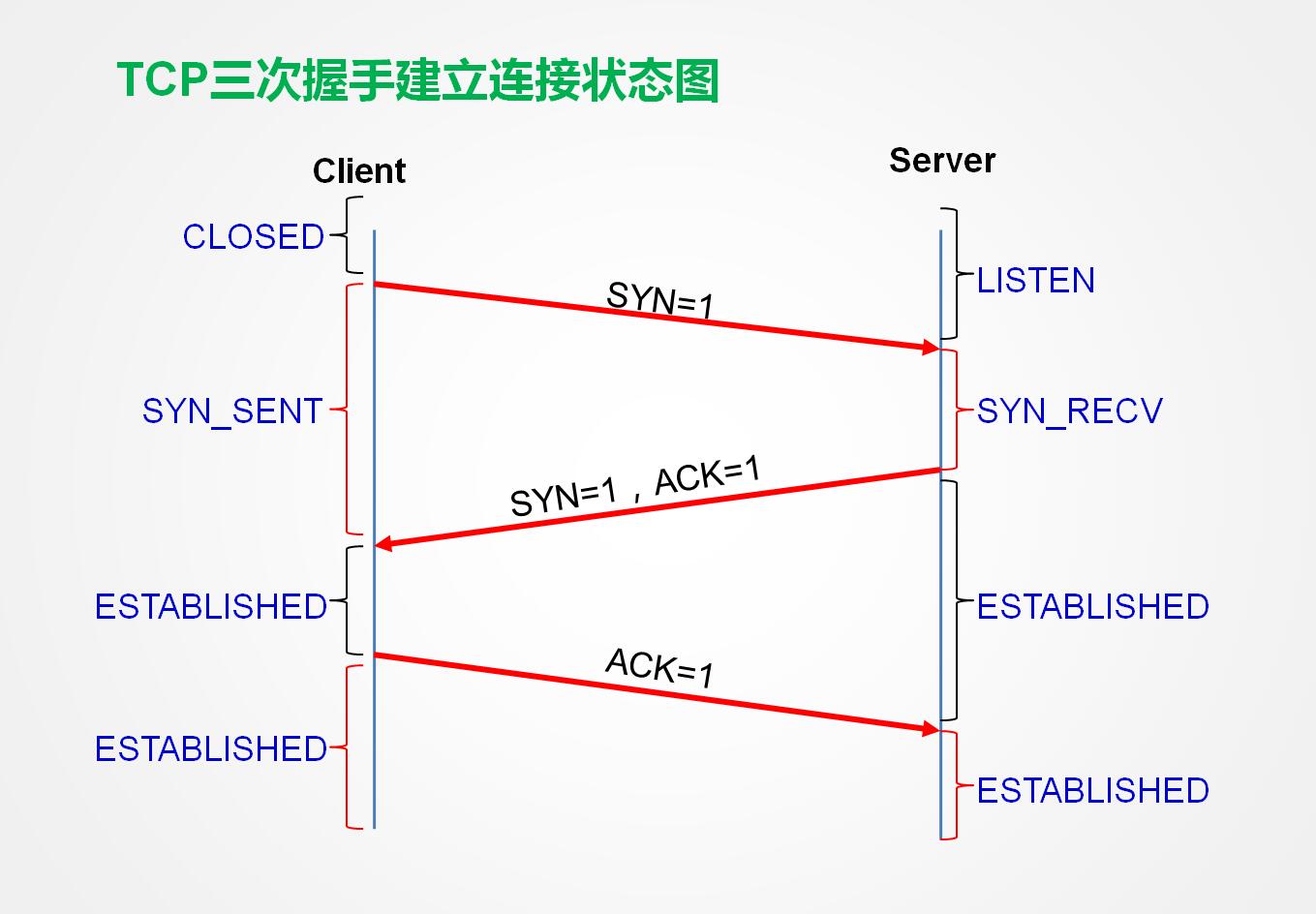
服务器处于监听状态,接受客户端发送的syn请求,并发送syn和ack给客户端,客户端接受到服务器的应答,再次发送ack应答给服务器,TCP三次握手建立。
- 断开请求状态
服务器:connection established—>close wait—>last ack—>closed
客户端:connextion established—>fin wait1–>fin wait2–>time wait—>closed
整个过程可以理解为TCP四次挥手: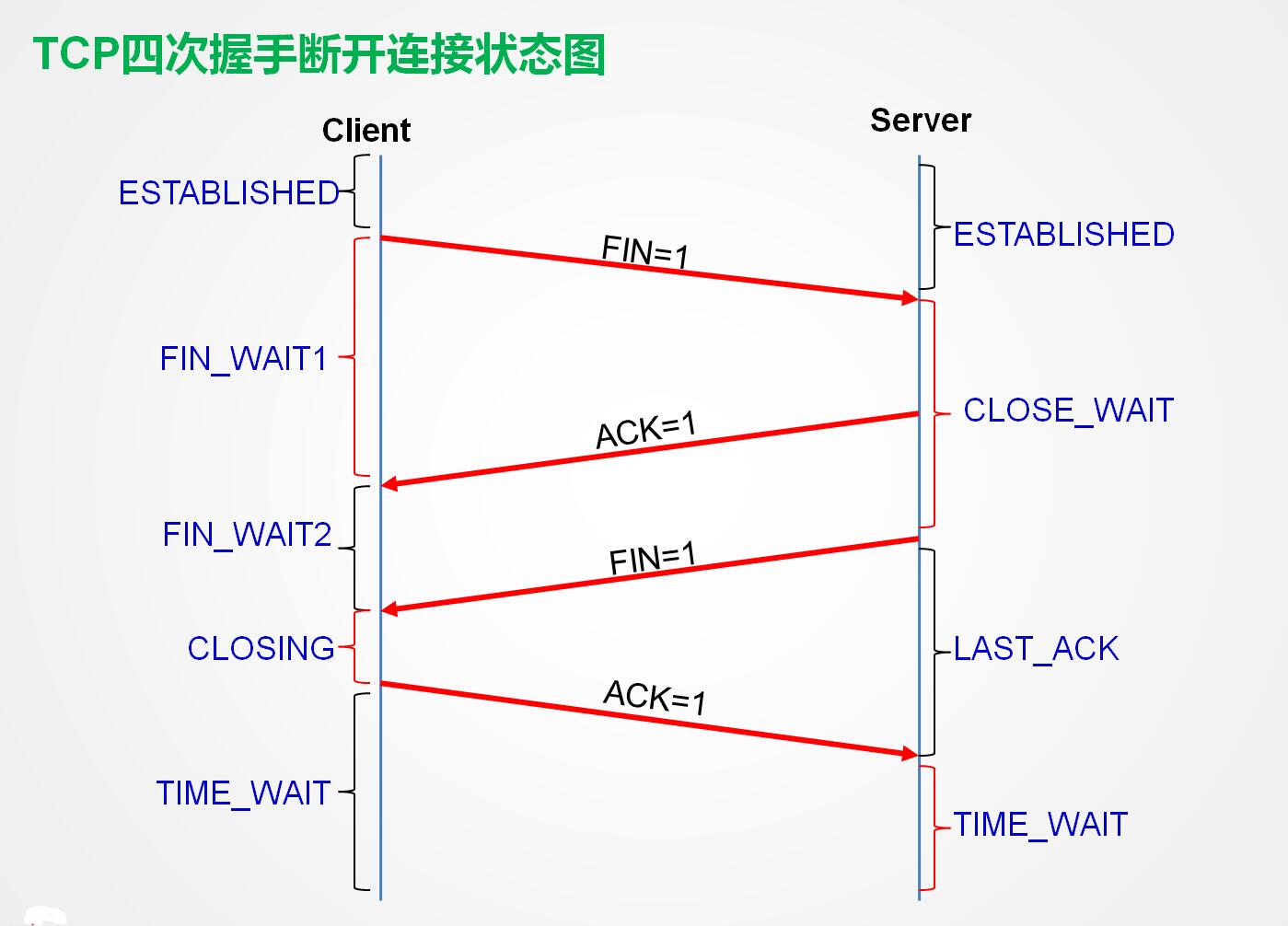
服务器处于连接状态,客户端向服务器端发送fin请求,服务器接受fin回答ack,进入close wait,待服务器处理完请求数据,主动发送ack,进入last ack,而这个时间段我们接受到客户端的ack回答,服务器端的连接就关闭了,而客户端发完ack后会进入time wait等待,因tcp连接都会有重传机制,这边的客户端等待是为了服务器端这个时间段里会不会发出重传请求,如果在这时间段里未收到数据重传的请求说明服务器端已经接受到了ack应答,正常关闭,所以客户端也可以正常关闭了。
内部服务请求
在服务器的运行过程中,服务器内部也会发生如上的状态机的变化,而这个过程中服务器端即是客户端也是服务器端。客户端服务端同时发送请求
服务器:closed—>syn sent—>syn recv—>connection established
客户端:closed—>syn sent—>syn recv—>connection established
服务器:connection established—>fin wait1—>closing—>time wait—>closed
客户端:connection established—>fin wait1—>closing—>time wait—>closed
两端同时发送请求连接或断开,单方都只需要一次请求应答
=================================================================
NET 优化
查看服务器中的TCP连接状况:
1 | ~]# netstat -na | awk '/^tcp/ {++T[$NF]}END {for (a in T) {print a,T[a]}}' |
我们知道有针对syn的ddos攻击,所以比较关心的就是在syn flood,所以我们可以调节的内核参数为:
- net.ipv4.tcp_synack_retries:默认为5,这个参数定义了内核在放弃连接之前所送出的syn+ack的数目,大约180秒左右。
- net.ipv4.tcp_syncookie=1:一般来说,net.ipv4.tcp_syncookie=1是用来防治ddos攻击的,syn flood攻击,是利用TCP三次握手的缺陷,当服务端处于syn recv的时候,客户端不发送确认包(三次握手无法实现),这个情况下服务器会重试(再次发送syn+ack),等待这个未完成的连接,这段时间称为syn timeout,一般时间是分钟级的(30秒-2分钟)。这种处于半连接状态的TCP连接,会存储在内核的半连接队列中,当sync recv的TCP的半连接溢出时,接下来的TCP连接将会直接被丢弃,这个典型的syn flood攻击。而能够有效防范syn flood攻击手段之一就是syn cookie,其工作原理是在TCP服务器收到TCP SYN包并返回TCP SYN+ACK包时,不分配专门的数据区,而是根据这个syn包计算出一个cookie值。在收到TCP ACK包时,TCP服务器再根据cookie检查这个TCP ACK包的合法性,如果合法,再分配专门的数据区进行处理未来的TCP连接。
- net.ipv4.tcp_max_orphans=262144:系统中最多有多少个tcp套接字不被关联到任何一个用户文件句柄上。如果超过这个数字,孤儿连接即刻被复位并打印出警告信息。这个限制仅仅是为了防治简单的ddos攻击,应该增大这个值(如果增加内存)
- net.ipv4.tcp_syn_retries=1:在内核放弃连接syn重试的次数
CLOSED_WAIT状态是服务端收到fin请求,而未发出ack的tcp状态,出现这样的情况基本是由于server端代码出现问题,如果出现大量CLOSED_WAIT状态,要考虑检查代码了。
TIME_WAIT根据TCP协议分析,处于主动关闭一方进入socket会进入TIME_WAIT状态,这个时间持续2个MSL,约4分钟,这样状态的socket是无法被回收利用的,如果出现大量短连接,并且由服务器主动关闭连接,服务器将会出现大量TIME_WAIT状态,导致socket耗尽,拒绝服务。
- net.ipv4.tcp_tw_resync=1:表示开启TCP连接中的TIME_WAIT 的socket的快速回收,默认为0
- net.ipv4.tcp_tw_reuse=1:表示开启重用,允许TIME_WAIT 的socket重新用于新的TCP连接,默认为0
- net.ipv4.tcp_max_tw_buckets=6000:TIME_WAIT的数量,默认180000
优化fin_wait2的等待时间
- net.ipv4.tcp_fin_timeout=10:默认60s,减少fin_wait_2状态的时间,对端可能出错并永远不关闭连接,甚至意外宕机。
端口请求队列优化:
- net.core.somaxconn=262144 定义系统(listen)每一个端口的最大监听队列的长度,默认128,对于高并发的服务太小了
- net.core.netdev_max_backlog=262144 每个端口接受的数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目
- net.core.optmem_max=81920 表示每个套接字所允许的最大缓冲区的大小
防治tcp连接序号回卷:
- net.ipv4.tcp_timestamps = 0
tcp保持连接的时长:
- net.ipv4.tcp_keepalive_time = 30: 间隔多久发送1次keepalive探测包,默认7200,相对于nginx等服务只是保持65秒的连接太大了
- net.ipv4.tcp_keepalive_intvl = 30: 探测失败后,间隔几秒后重新探测,默认75秒
- net.ipv4.tcp_keepalive_probes = 3: 探测失败后,最多尝试探测几次,默认9次
允许系统打开的端口:
- net.ipv4.tcp_local_port_range=1024 65000: 根据业务尽量避免业务端口的使用
tcp/ip协议栈的设置:
- net.core.rmem_default=8388608:默认的TCP数据接收窗口大小(字节)
- net.core.rmem_max=16777216:最大的TCP数据接收窗口大小(字节)
- net.core.wmem_default=8388608:默认的TCP数据发送窗口大小(字节)
- net.core.wmem_max=16777216:最大的TCP数据发送窗口大小(字节)
- net.ipv4.tcp_mem = 94500000 915000000 927000000:内存使用的下限 警戒值 上限(内存页)
- net.ipv4.tcp_rmem = 4096 87380 16777216:socket接收缓冲区内存使用的下限 警戒值 上限(内存页)
- net.ipv4.tcp_wmem = 4096 16384 16777216:socket发送缓冲区内存使用的下限 警戒值 上限(内存页)
网络追踪设置,如果服务像nat转换ip等功能,连接过多可能就会爆满内核的连接追踪表,我们可以设置短点的超时时间或设置大点的追踪数目:
- net.netfilter.nf_conntrack_tcp_timeout_established = 600 默认43200
- net.netfilter.nf_conntrack_max = 655350 默认65535
启用有选择的应答(1表示启用),通过有选择地应答乱序接收到的报文来提高性能,让发送者只发送丢失的报文段,(对于广域网通信来说)这个选项应该启用,但是会增加对CPU的占用。
- net.ipv4.tcp_sack=1
启用转发应答,可以进行有选择应答(SACK)从而减少拥塞情况的发生,这个选项也应该启用。
- net.ipv4.tcp_fack = 1
启用RFC 1323定义的window scaling,要支持超过64KB的TCP窗口,必须启用该值(1表示启用),TCP窗口最大至1GB,TCP连接双方都启用时才生效。
- net.ipv4.tcp_window_scaling = 1
对于还未获得对方确认的连接请求,可保存在队列中的最大数目。如果服务器经常出现过载,可以尝试增加这个数字。
- net.ipv4.tcp_max_syn_backlog=2048
路由功能:
- net.ipv4.ip_forward=0
开启反向路径过滤
- net.ipv4.conf.default.rp_filter = 1
禁用ip源路由
- net.ipv4.conf.default.accept_source_route = 0
kernel 优化
进程间信息设置:
- kernel.msgmax=65535:以字节为单位规定信息队列中任意信息的最大允许的大小。这个值一定不能超过该队列的大小,默认65535
- kernel.msgmnb=65535:以字节为单位规定单一信息队列的最大值,kernel.msgmnb>=kernel.msgmax
- kernel.msgmni=1985:规定信息队列的最大数量(即队列的最大数量)。64位架构机器默认为1985,32位架构机器默认1736
共享内存设置:
- kernel.shmall=18446744073692774399:以字节为单位规定一次在该系统中可以使用的共享内存总量
- kernel.shmmax=18446744073692774399:以字节为单位内核可允许的最大共享内存 kernel.shmmax>=kernel.shmall
- kernel.shmmni=4096:规定系统范围内的最大共享内存片段
线程设置:
- kernel.threads-max=14521:规定一次使用的最大线程数
使用sysrq组合键是了解系统目前运行情况,为安全起见设为0关闭
- kernel.sysrq = 0
控制core文件的文件名是否添加pid作为扩展
- kernel.core_uses_pid = 1
MEM 优化
与内存容量配置相关:
判断决定是否接受接受超大内存请求:
- vm.overcommit_memory=0
(1)0:默认设置,内存执行启发式内存过量使用处理,方法是估计可用内存量,并拒绝明显无效的请求。遗憾的是因为内存是使用启发式而非精准算法计算进行部署,这个设置有时可能会造成系统的可用内存超载
(2)1:内核执行无内存过量处理。使用这个设置会增大内存超载的可能性,但也增强大量使用内存任何性能。
(3)2:内存拒绝等于或者大于总可用swap大小以及overcommit_radio指定的物理RAM比例的内存请求。如果你希望减少内存过度使用的风险,这个是最好的设置。 - vm.overcommit_radio=50:当启用overcommit_memory=2的时候,这个值会起作用
虚拟内存相关:
- vm.swappiness:参考值可为0-100,控制系统swap的程序,高数值可以优先系统性能,在进程不活跃时主动将其装换出物理内存。低数值可优先互动性并尽量避免将进程装换出物理内存,并降低反应延迟。默认值为30
- vm.min_free_kbytes:保证系统间可用的最小kb数,这个值用来计算每个低内存区的水印值,然后为其大小按比例分配保留的可用页。当设置过大,内存可能很快就不足。但设置过小,系统可能会让OOM杀死进程
- vm.dirty_radio:规定百分比。单个进程,当脏数据组成达到系统内存总数的这个百分比后开始写下脏数据(pdflush),就是将内存的数据写入存储
- vm.dirty_background_radio:规定百分比。全部,当脏数据组成达到系统内存总数的这个百分比后开始写下脏数据(pdflush)
- vm.drop_caches:当程序内存泄漏的时候,这个可以临时清除些内存,一般设置1
(1)系统无效并释放所有页缓冲内存
(2)系统释放所有未使用的slab缓冲内存
(3)系统释放所有页缓冲和slab缓冲内存
CPU 优化
我们可以想nginx配置中定义服务进程对与那颗cpu的亲和度:
1 | ps axo psr,comm,pid |
- taskset -p -c cpu1,cpu2 pid
隔离cpu
在/etc/grub.conf
kernel … ioslcpus=cpu number,cpu number 启动时隔离cpu
我们也可以定义中断在那颗cpu上发生,但不建议去设置:
查看中断interrupts /proc/interrupts
echo cpunumber,… > /proc/irq/#/sm_affinity
这里使用的cpu应该为isolcpus中定义cpu集合之外的其他cpu,不建议,容易造成系统不稳定
进程优化
进程优先级:0-139
- 实时优先级:1-99,越大优先级越高
- 动态优先级:100-139,越小优先级越高
进程调度类别:
- SCHED_FIFO,先进先出基于堆的调度,实时
chrt -f [1-99] /path/to/program arguments - SCHED_RR:基于轮询的调度,实时
chrt -r [1-99] /path/to/program argumenets - SCHED_NORMAL,SCHED_OTHER:100-139
nice,renice
当一个执行占据CPU时钟周期的进程,会收到内核的惩罚,被降低优先级,这个时候我们可以调整该进程为实时优先级调度。